Introduction to Fine-tuning Large Language Models
I've been wanting to write an introduction on how to fine-tune large language models for a while now because it's such a vast and under-documented area, especially when it comes to the libraries, hyperparameters, and techniques involved. In short, fine-tuning allows us to adapt models for specific downstream tasks, improve performance on domain-specific problems, align model behavior with human preferences, and create specialized variants of base models. This is useful for a wide range of applications both in business and pure research.
Pre-training, Fine-tuning and Post-training
This is contrast to pre-training, which is the foundational phase in developing a large language model. During pre-training, the model learns general language understanding from massive text corpora. For example, Llama 3 was trained on approximately 15.2 trillion tokens. This process involves initializing random tensors and training them to recognize statistical patterns and relationships between words and concepts.
The pre-training phase requires immense computational resources, often costing millions of dollars and requiring specialized hardware setups. Organizations typically use hundreds or thousands of GPUs running in parallel for weeks or months to complete pre-training. During this phase, the model learns through self-supervised techniques like causal language modeling, where it predicts the next token in a sequence given the preceding context.
Post-training refers to the phase after fine-tuning where additional techniques are applied to further refine and optimize the model's performance. This phase often includes Reinforcement Learning from Human Feedback (RLHF), where models learn to align their outputs with human preferences through feedback and reward signals. Preference optimization is another key aspect, focusing on adjusting the model to better meet specific user needs or ethical guidelines. These techniques aim to enhance the model's usability, safety, and efficiency in real-world applications by ensuring that its behavior aligns with desired outcomes and values.
Fine-tuning builds upon a pre-trained model by further training it on a smaller, task-specific dataset. This process adapts the model's existing knowledge to specific downstream tasks while preserving the foundational understanding gained during pre-training. Traditional fine-tuning updates all model parameters, which requires substantial computational resources - typically 160-192GB of GPU memory for a 7B parameter model.
The fine-tuning process is particularly effective because it leverages the knowledge embedded in the pre-trained weights. For example, the LIMA paper demonstrated that fine-tuning a 65B parameter LLaMA model on just 1,000 high-quality instruction-response pairs could achieve performance comparable to GPT-3. However, this approach requires careful dataset curation and sufficient GPU resources to handle the full model parameters.
Main Steps
In our fine-tuning setup we're goign to use a pre-trained model and then adapt it to our custom use case.
-
Data Preparation:
- Collect and preprocess data
- Create datasets with instructions and responses
- Split into training, validation, and test sets
-
Model Initialization:
- Load a pre-trained model and tokenizer
- Configure model architecture and hyperparameters
- Initialize model weights and apply LoRA adaptations
-
Training:
- Configure training parameters
- Train the model on the training dataset
- Monitor training loss and eval loss
-
Post-Training (Optional):
- Apply additional techniques like DPO, KTO or PPO to align model behavior
-
Compression and Quantization (Optional):
- Apply compression and quantization techniques to optimize model size and inference speed
- Evaluate and test the final model
In our setup we'll be using the transformers library from Hugging Face. It has many knobs and dials to control the training process which can be quite daunting so we'll go thorugh each class of these arguments and describe both the theory and practice.
These are generally configured using the TrainingArguments class. These arguments include settings such as the number of training epochs, batch size, learning rate, and other hyperparameters that influence the training dynamics and performance of the model. Properly configuring these arguments is crucial for achieving optimal results and efficient training.
Below is the basic scaffold of a model training loop.
from transformers import TrainingArguments
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import SFTTrainer
# Step 1: Load the training dataset
train_dataset = datasets.load_dataset(
"path/to/train/dataset"
)
# Step 2: Load the model
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-3B-Instruct",
quantization_config=bnb_config
)
# Step 2: Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-3.2-3B-Instruct"
)
# Step 3: Training
training_args = TrainingArguments(
# ...
output_dir="path/to/save/model"
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
# ...
)
trainer.train()
# Step 4: Post-Training
# Step 5: Compression and Quantization
In addition in order to start working with these python libraries we'll neeed to install a few dependencies.
# Install PyTorch
pip install "torch==2.4.0"
pip install "transformers==4.44.2"
pip install "datasets==2.21.0"
pip install "accelerate==0.33.0"
pip install "evaluate==0.4.2"
pip install "bitsandbytes==0.43.3"
pip install "trl==0.9.6"
pip install "peft==0.12.0"
# Install Flash Attention
pip install ninja packaging
pip install flash-attn --no-build-isolation
Most of the arguments we'll dicuss below are configured in the TrainingArguments class. Let's walk through some of the most important ones.
Pre-trained Models
There two main types of models that are widely used causal and masked. Causal language models predict the next token in a sequence of tokens, and the model can only attend to tokens on the left. This means the model cannot see future tokens. On the other hand masked language modeling predicts a masked token in a sequence, and the model can attend to tokens bidirectionally. We're only going to focus on causal models in this guide.
Of the causal models, we are going to focus on autoregressive generative pre-trained transformer models. Autoregressive models are a class of models that predict the next token in a sequence by conditioning on the previous tokens. They generate each token step-by-step, using the output of the previous step as part of the input for the next step. They also use an attention mechanism to attend to previous tokens. The theory of generative transformers is well-described by many other sources so I won't go into much detail here.
There are many pre-trained transformers that are now available on HuggingFace. The most common ones are:
- Llama 3.1 Family - Meta's flaghship open source models ranging from 8B, 70B to 420B parameters, available in base and chat-tuned variants. These are the most widely used models for fine-tuning and have performance that rival closed models.
- Llama 3.2 Family - Meta's open source models ranging from 1B to 3B parameters. These models punch above their weight class and are very strong for such small sizes.
- Mistral Family - Including the 7B base model and Mixtral 8x7B mixture-of-experts model. Offers competitive performance with smaller parameter counts.
- Phi-3.5 - Microsoft's 2.7B parameter model that shows strong reasoning capabilities despite its small size. These models can work well on linguistic tasks but many people have difficulty training them on coding or other non-linguistic tasks.
- Gemma - Google's recently released family of open models in 2B and 7B sizes. Similar performance to Phi-3.5.
If you don't know where to start, I recommend using the Llama 3.1 family as your base model starting with a 8B parameter model and scaling up to higher parameter counts as needed. However when scaling up to larger models you will need to acquire more VRAM to do the fine-tune which may complicate your training setup and increase your costs.
There is also the matter of licensing. The models from Meta are under a bespoke Llama license which allows you access to use the model but requires you to comply with certain restrictions when using it for commercial purposes. The Gemma models are also under a bespoke Google license that limits some commercial use. The Mistral models are under a permissive Apache license which allows most uses with attribution. The Phi models are under an MIT license which is also very permissive and allows all uses.
Parameter Count
The number of parameters in a model is a crucial metric that indicates the model's size and complexity. It determines the number of weights the model has, which directly influences the amount of data it can process and the computational resources required for training and inference.
As a convention most models have a name which includes the number of parameters. For example, meta-llama/Llama-3.2-3B-Instruct has 3 billion parameters.
Instruct Modelels vs Base Models
Base models are trained on general text data to learn language patterns and generate text, while instruct models are fine-tuned versions specifically trained to follow instructions and respond to prompts. For example, Llama-3.2-3b is a base model, while Llama-3.2-3b-instruct is fine-tuned to better understand and execute user instructions.
The base model is typically used for more general purpose tasks, while the instruct model is used for more specific tasks like chat or instruction following. For the sake of fine-tuning we'll almost always use the instruct model with a chat template.
GPU Cloud Vendors
In order to get started with fine-tuning, you'll need to get your hand on some GPUs. Typically you'll need either 1-2 high-end GPUs (A100, H100) or 4-8 mid-range GPUs (A100, A6000, V100). It's usually easier to just get a few H100 SXM GPUs as they have the best performance rather than trying to piece together a cluster of smaller GPUs.
SXM, PCIe and NVL refer to three different GPU form factors and interconnect technologies that are commonly used in machine learning workloads.
-
SXM GPUs are designed specifically for data center and server environments. They feature a direct connection to the CPU via NVLink, enabling much higher memory bandwidth (up to 900 GB/s) compared to traditional connections. These cards are built with an optimized thermal design that allows for sustained high performance under heavy workloads. However, SXM cards require specialized server hardware and are generally more expensive than their PCIe counterparts.
-
PCIe GPUs, on the other hand, use the standard PCIe slot connection found in most computers and servers. While they have lower memory bandwidth (up to 64 GB/s), they offer more flexible installation options and work with standard server hardware.
-
NVL / NVLink is a high-speed interconnect technology developed by Nvidia that allows GPUs to communicate directly with each other, bypassing the slower PCIe bus. This enables faster data transfer and improved performance for parallel computing tasks. NVL has a peak bandwidth of 4,000 gigabytes per second (GBps).
For fine-tuning large language models, SXM cards generally provide better performance due to their higher memory bandwidth and optimized thermal design. However, PCIe cards are more accessible and still very capable for most fine-tuning workloads. The choice between the two often comes down to budget constraints and specific performance requirements.
Fortunately, because of a glut of venture capital funding there are many cloud vendors competing for your business. Generally they will rent you a variety of GPU types and sizes. Since most of these companies are operating on razor thin margins, or grossly unprofitable, they are always trying to out-do each other with better pricing and availability. It's unclear how long this will last, but for now it's a good time to be a consumer of GPU cloud services.
The most common GPU types you can get are:
| GPU Type | VRAM | Typical Use Case | Approx. Cost/hr | Notes |
|---|---|---|---|---|
| H200 SXM | 141GB | Large model training (70B+) | $3.99-4.29 | - Newest GPU - Optimal performance for large models - Ideal for 70B parameter models |
| GH200 | 96GB | Large model training (70B+) | $2.99-3.29 | - Good performance for large models - Ideal for 70B parameter models |
| H100 NVL | 94GB | Large model training (70B+) | $2.99-3.29 | - Optimal performance for large models - Ideal for 70B parameter models |
| H100 SXM | 80GB | Large model training (70B+) | $2.79-3.29 | - Good performance for large models - Ideal for 70B parameter models |
| H100 PCIe | 80GB | Large model training | $2.49 | - Slightly lower bandwidth than SXM - Good for 70B parameter models |
| A100 SXM | 80GB | Medium/Large training (7-70B) | $1.79 | - Great price/performance ratio - Good for models up to 70B - Supports Flash Attention 2 |
| A100 PCIe/SXM | 40GB | Medium model training (7-13B) | $1.29 | - Good for models up to 13B - Popular for fine-tuning |
| A10 | 24GB | Small model training (<7B) | $0.75 | - Good for models up to 7B - Budget-friendly option |
| A6000 | 48GB | Medium model training | $0.80 | - Good alternative to A100 - Better price/performance |
| V100 | 16GB | Small model training (<7B) | $0.55 | - Older architecture - Limited by VRAM - Budget option |
To get a rough estimate of the cost of fine-tuning a model, we can use the following rough estimates:
Fine-tuning a 7B model (24 hours)
- H100 SXM: ~$72/day
- A100 80GB: ~$43/day
- A100 40GB: ~$31/day
- A10: ~$18/day
- V100: ~$13/day
Fine-tuning a 13B model (24 hours)
- H100 SXM: ~$72/day
- A100 80GB: ~$43/day
- A100 40GB: ~$31/day
Fine-tuning a 70B model (24 hours)
- H100 NVL: ~$74/day
- H100 SXM: ~$72/day
- 2 x A100 80GB: ~$86/day
The vendors will typically charge you for the GPU time, storage, and data transfer which can add up quickly. The following is a list of popular GPU cloud vendors:
- Lambda Labs - Competitive pricing, good availability
- RunPod - Spot instances, community templates
- Vast.ai - Marketplace for renting GPUs
- CoreWeave - Enterprise-focused, high availability
- Google Cloud - Wide selection, global availability
- AWS - Extensive options, but can be expensive
- Azure - Good enterprise integration
- Paperspace - Developer-friendly, Jupyter integration
- Genesis Cloud - Budget-friendly options
Unless you are already an existing Google Cloud or AWS customer, you'll probably want to start with Lambda Labs or RunPod as they are most user-friendly and have the best developer experience.
Multi-GPU Setups
If you're doing more advanced research you meed require even more powerful hardware than individual GPUs, NVIDIA offers specialized solutions like the GH200 Grace Hopper Superchip and HGX clusters. The GH200 is a so called "superchip" that combines a CPU and GPU on a single chip with a 900GB/s NVLink-C2C connection between the processor and accelerator and 576 GB of coherent memory.
The first generation HGX platforms take this a step further by combining multiple GPUs into a single system optimized for AI workloads. The HGX H100 platform, for example, can scale up to 8 H100 GPUs interconnected with NVLink, providing 3.6TB/s of bisectional bandwidth between GPUs.
The second generation DGX B200 is features eight NVIDIA Blackwell GPUs with NVLink interconnect, which have 3x the training performance and 15x the inference performance compared to previous generations. The setup includes 1,440GB of total GPU memory, delivers 72 petaFLOPS for training and 144 petaFLOPS for inference.
For the largest training jobs, organizations can deploy multiple DGX/HGX nodes connected via Quantum-2 InfiniBand networking to effectively create supercomputing systems. These multi-GPU setups can easily run into the multi-million dollar range. For example, the Llama 3 model was trained on 16,000 H100 GPUs ($30k a pop), running for 54 days of continuous training time. The largest clusters in the world today have nearly 100,000 GPUs.
In general there are three frameworks that you would use to setup multi-GPU training:
HuggingFace Accelerate provides the simplest path to distributed training, acting primarily as a wrapper around PyTorch's distributed functionality. While it excels at basic multi-GPU training and inference scenarios and integrates smoothly with both DeepSpeed and FSDP, it has limitations when used alone. Notably, Accelerate offers limited model sharding capabilities and can only use device_map="auto" with a single process. This makes it unsuitable for sophisticated model parallelism without leveraging additional tools.
Microsoft DeepSpeed offers more advanced capabilities through its Zero Redundancy Optimizer, which provides three stages of optimization. Its ZeRO-Infinity feature enables training of massive models by allowing parameter offloading to CPU and NVMe storage, achieving excellent memory efficiency with no parameter replication across GPUs. However, these advantages come with increased complexity in setup and configuration. The CPU/NVMe offloading, while enabling training of larger models, can significantly impact training speed. Users must carefully configure stages and offloading parameters to achieve optimal performance.
PyTorch FSDP is a middle ground, offering native integration with PyTorch since version 1.11. It can serve as a drop-in replacement for DistributedDataParallel and supports CPU offloading similar to DeepSpeed. However, being a relatively newer solution compared to DeepSpeed, it may require more PyTorch-specific knowledge to implement effectively.
For most basic multi-GPU training needs, Accelerate provides sufficient functionality. However, when training very large models that exceed single GPU memory capacity, either DeepSpeed or FSDP becomes necessary. DeepSpeed's longer history and multiple optimization stages make it a proven choice for large-scale training, while FSDP's tight PyTorch integration might appeal to teams already deeply invested in the PyTorch ecosystem.
I can't offer much advice about multi-GPU training as typically if you need to train models of this size you have very specialized needs and will need a bespoke training software setup and custom hardware. So I won't go into much detail here. There are other guides from the major model labs that go into more detail on this topic. See my post on DeepSpeed for some surface level information on this kind of cluster setup.
Parameter-Efficient Fine-tuning (PEFT)
Compared to full-tuning, the most common technique for fine-tuning large language models is parameter-efficient fine-tuning (PEFT). This is in contrast to full-tuning, which involves updating all model parameters during fine-tuning, which requires substantial computational resources and memory. In contrast, PEFT methods have revolutionized how we adapt large language models by dramatically reducing computational requirements while maintaining performance. Rather than updating all model parameters, PEFT methods strategically modify only a small subset of parameters or introduce a limited number of new trainable parameters, making the process much more efficient.
The most prominent PEFT technique is Low-Rank Adaptation (LoRA), which has become the de facto standard for efficient model adaptation. LoRA works by adding small trainable rank decomposition matrices to specific layers of the model while keeping the pre-trained weights frozen. This approach can reduce the number of trainable parameters by up to 10,000 times and GPU memory requirements by over 3 times compared to full fine-tuning.
When combined with 4-bit quantization techniques (QLoRA), the memory savings become even more dramatic. QLoRA enables the training of models as large as 70 billion parameters on consumer-grade hardware like NVIDIA RTX 3090s - a task that would traditionally require 16 or more A100-80GB GPUs. QLoRA achieves this through several key innovations:
- It performs backpropagation through a frozen, 4-bit quantized pre-trained model into Low-Rank Adapters
- It introduces a new data type called 4-bit NormalFloat (NF4) that is specifically optimized for normally distributed weights
- It implements double quantization to reduce memory footprint by quantizing the quantization constants themselves
- It uses paged optimizers to handle memory spikes during training
The effectiveness of QLoRA stems from its ability to maintain full 16-bit fine-tuning task performance while drastically reducing memory requirements. This makes it possible to fine-tune large models on a single GPU that would normally require a cluster of high-end GPUs.
LoRA Parameters
When doing a LoRA fine-tune there are several core parameters which define the behavior of the fine-tuning process:
LoRA Rank (r)
The LoRA rank determines the number of rank decomposition matrices used. Think of it like the number of "learning dimensions" the model has available - with a higher rank, the model can learn more nuanced and complex patterns, similar to how having more neurons in a neural network allows it to model more sophisticated relationships. However, just like adding more neurons, a higher rank requires more memory and computation power. The original LoRA paper recommends starting with a rank of 8 as a good balance point. For simpler tasks like basic text classification this may be plenty, but for more complex tasks like creative writing or complex reasoning, you might want to bump it up to 16 or 32. Just keep in mind that higher ranks will need more GPU memory and take longer to train.
LoRA Alpha
The alpha parameter acts as a scaling factor that determines how much influence the LoRA adaptations have compared to the frozen pre-trained weights. Think of it like a volume knob - a higher alpha means the LoRA changes speak louder compared to the original model's voice, while a lower alpha keeps the changes more subtle. It helps control the magnitude of updates during training. The relationship between rank and alpha is important - typically alpha is set to 2x the rank value as a starting point (so if rank is 8, alpha would be 16). This scaling helps ensure stable training while allowing meaningful updates to occur, kind of like finding the sweet spot on that volume knob where you can clearly hear the changes without drowning out the original sound.
LoRA Dropout
Dropout is a regularization technique used in machine learning to prevent overfitting. It works by randomly dropping out (setting to zero) a certain percentage of neurons during training. This forces the remaining neurons to learn more robust and generalized features, reducing their reliance on specific patterns that may not generalize well to unseen data. In the context of LoRA, dropout is applied to the low-rank adaptation matrices during training. By introducing dropout, we ensure that the model does not become overly dependent on any single adaptation path, promoting better generalization and robustness. As a very rough analogy, think of it like a football team where occasionally, some players are benched randomly during practice. This forces the remaining players to step up and improve their skills, making the whole team stronger and more versatile.
Common default values for LoRA dropout typically range from 0.0 to 0.3. A dropout rate of 0.05 is often a good starting point, providing a balance between regularization and maintaining enough active neurons for effective learning. If the model still shows signs of overfitting, you might increase the dropout rate to 0.2 or 0.3. If you are training a large number of layers in your LoRA adapter, you might want to increase the dropout rate to compensate for the increased number of layers.
LoRA Bias
The bias parameter in LoRA refers to the additive term added to the output of the low-rank adaptation matrices. It allows the model to learn an additional offset from the input, providing a more flexible and dynamic response. Bias terms are particularly useful in situations where the input data has a non-zero baseline or when the relationship between input and output is not purely linear. By adding a bias, the model can better capture and adjust for such variations, improving its overall performance and generalization.
The default value for bias is "none" which means that no bias is added. However, in some cases you may want to add a bias term to the LoRA adaptation matrices. The other options are "all" and "lora_only" which add a bias term to all the matrices or just the LoRA matrices respectively.
LoRA Target Modules
The selection of target modules in LoRA represents a critical architectural decision that directly impacts both the model's adaptability and computational efficiency. In transformer-based architectures, these modules consist of various projection matrices and components that handle different aspects of the model's processing pipeline.
-
The embedding layer (
embed_tokens) serves as the model's initial interface with input tokens, transforming discrete token IDs into continuous vector representations. While it's possible to include embeddings as a LoRA target, this is generally discouraged as it can significantly increase memory usage without proportional gains in model performance. The embedding layer typically contains a large number of parameters due to vocabulary size, making it less efficient for LoRA adaptation. -
The normalization layers (
norm) help stabilize the network's internal representations by standardizing activation values. These layers contain relatively few parameters and are crucial for maintaining stable training dynamics. However, they are rarely targeted for LoRA adaptation because their role is primarily statistical normalization rather than learning complex patterns. Including norm layers in LoRA targets typically offers minimal benefit while potentially destabilizing training. -
The language modeling head (
lm_head) is responsible for converting the model's internal representations back into vocabulary-sized logits for token prediction. While this layer is crucial for the final output, including it as a LoRA target is generally unnecessary. Thelm_headoften shares weights with the embedding layer through weight tying, and adapting it separately can break this symmetry without providing significant benefits. -
The core attention mechanism components remain the most effective targets for LoRA adaptation. The query projection matrix (
q_proj) transforms input embeddings into query vectors, determining how the model searches for relevant information within its context. The key projection matrix (k_proj) creates key vectors that help establish relationships between different parts of the input, while the value projection matrix (v_proj) transforms the input into value vectors that contain the actual information to be extracted. These three projections form the cornerstone of the self-attention mechanism, withq_projandv_projoften being the most crucial targets for adaptation. -
The output projection matrix (
o_proj) processes the combined attention outputs before they move to subsequent layers. This transformation ensures the attention mechanism's output maintains compatibility with the model's broader architecture. In models with more complex architectures, you'll also find the upward projection (up_proj) and downward projection (down_proj) matrices, which handle dimensionality transformations between layers.
When using LoRA for fine-tuning, it's recommended to start with a focused approach targeting just the attention components:
lora_config = LoraConfig(
target_modules=["q_proj", "v_proj"],
r=8,
lora_alpha=16,
lora_dropout=0.1
)
For more demanding tasks or when initial results aren't satisfactory, you can expand to include additional projection matrices:
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
r=16,
lora_alpha=32,
lora_dropout=0.1
)
In order to fine-tune a model using PEFT, you'll need to install the transformers, peft, and trl libraries. Here's an example of how to configure and fine-tune a LoRA model.
from peft import LoraConfig, PeftModel
# QLoRA parameters
lora_config = LoraConfig(
r=64, # LoRA attention dimension
lora_alpha=16, # LoRA scale factor
lora_dropout=0.1, # Dropout probability
bias="none",
task_type="CAUSAL_LM"
)
lora_model = get_peft_model(model, lora_config)
lora_model.print_trainable_parameters()
# trainable params: 1,572,864 || all params: 332,769,280 || trainable%: 0.472659014678278
Most often tweaking LoRA hyperparameters is not the most efficient use of your time. So I recommend starting with the defaults and only adjusting if you are seeing clear signs of overfitting or underfitting. The biggest gains will most often come from better dataset curation rather than hyperparameter tuning. However if you are going sweep through values you can try the following sets of parameters that might give good results, in increasing order from the default:
- r=16, lora_alpha=16
- r=16, lora_alpha=32
- r=32, lora_alpha=64
- r=64, lora_alpha=128
- r=128, lora_alpha=256
- r=256, lora_alpha=512
For example, to use a rank of 256 and an alpha of 128 over all linear layers use the following configuration:
peft_config = LoraConfig(
r=256,
lora_alpha=128,
lora_dropout=0.05,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
)
Quantized LoRA
To use QLoRA, you'll also need to install the bitsandbytes library as well.
# 4-bit quantization config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
Loading the Model
When loading a pre-trained model from Hugging Face's model hub, you'll use the from_pretrained() method. This method downloads the model weights and configuration from the specified repository. The model architecture and weights are automatically determined based on the repository name.
You can control the precision of the loaded model weights using the torch_dtype parameter. Common options include:
torch.float32(default): Full precision, uses more memory but highest accuracytorch.float16: Half precision, reduces memory usage while maintaining good accuracytorch.bfloat16: Google Brain floating point, better numerical stability than float16
For example, to load a model using 4-bit quantization specific to our QLoRA configuration from above:
from peft import prepare_model_for_kbit_training
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-3B-Instruct",
quantization_config=bnb_config
)
model = prepare_model_for_kbit_training(model)
The files that are fetched from Hugging Face will look like this:
├── config.json
├── generation_config.json
├── model-00001-of-00002.safetensors
├── model-00002-of-00002.safetensors
├── model.safetensors.index.json
├── special_tokens_map.json
├── tokenizer.json
└── tokenizer_config.json
The files each contain different information:
config.json: Contains the model's architecture configuration and hyperparametersgeneration_config.json: Stores settings for text generation like temperature and top-p samplingmodel-00001-of-00002.safetensors: First part of the model weights stored in SafeTensors formatmodel-00002-of-00002.safetensors: Second part of the model weights stored in SafeTensors formatmodel.safetensors.index.json: Index file mapping weight tensors to their locations in the split filesspecial_tokens_map.json: Maps special tokens like<|endoftext|>to their IDstokenizer.json: Contains the tokenizer's vocabulary and configurationtokenizer_config.json: Additional tokenizer settings and parameters
SafeTensors is a file format designed specifically for storing model weights and tensors. It was created as a safer and more efficient alternative to Python's pickle format, which can execute arbitrary code and pose security risks. The .safetensors files are typically very large (often multiple gigabytes) as they contain the actual learned parameters (weights) of the model.
These files store the model's weights as raw numerical arrays in a binary format, organized by layer. For a transformer model, this includes the attention layer weights and biases, feed-forward network parameters, layer normalization parameters, embedding matrices, and position encoding weights.
The weights are split across multiple files (like model-00001-of-00002.safetensors) because individual files can become too large to handle efficiently. Each file can be 10GB or larger for modern language models. The splitting also enables parallel downloading and more efficient memory mapping.
SafeTensors provides significant advantages through its memory-efficient loading via memory mapping, fast serialization and deserialization speeds, built-in type safety and validation, and elimination of security vulnerabilities from arbitrary code execution. This makes it an ideal format for storing and distributing large language models where safe and efficient handling of massive weight files is crucial.
There are three common file formats used for storing model weights:
-
.pth- PyTorch's native format that uses Python's pickle serialization. While widely used, it has security concerns since pickled files can execute arbitrary code. It's mainly used for PyTorch models and research projects. -
.safetensors- A modern format designed specifically for ML models that provides better security and performance than .pth files. It's memory-efficient, fast to load, and prevents code execution vulnerabilities. This is becoming the standard format for Hugging Face models. -
.gguf- The "GPT-Generated Unified Format" used by llama.cpp and similar projects. It's optimized for inference on consumer hardware, supporting various quantization methods. The format is compact and designed for efficient loading of quantized models.
The models are typically stored in the HuggingFace cache on your local machine. Which is usually located at ~/.cache/huggingface/hub. If you download many models this folder can get quite large. So it's a good idea to clean it up periodically.
Loading the Tokenizer
The tokenizer is used to convert text into tokens, which are the basic units of data processed by the model. The tokenizer also handles special tokens and provides various configuration options for text processing.
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-3.2-3B-Instruct",
)
The primary configuration options for the tokenizer are:
| Parameter | Description | Values |
|---|---|---|
padding_side |
Determines which side padding tokens are added | "right" (default) or "left" |
truncation_side |
Determines which side text is truncated when exceeding max length | "right" (default) or "left" |
chat_template |
Jinja template for formatting chat messages | String template following chat templating spec |
model_input_names |
List of inputs accepted by model's forward pass | e.g., ["input_ids", "attention_mask"] |
In addition to the above, the tokenizer also handles special tokens which are given special names and specific to the model architecture. For example:
| Token | Description |
|---|---|
bos_token |
Beginning of sequence token |
eos_token |
End of sequence token |
unk_token |
Token for unknown words |
sep_token |
Separator token between sentences |
pad_token |
Padding token for batch processing |
When encoding text, the tokenizer can return tensors in different formats:
| Return Type | Description | Example |
|---|---|---|
tf |
TensorFlow tensors | return_tensors="tf" |
pt |
PyTorch tensors | return_tensors="pt" |
np |
NumPy arrays | return_tensors="np" |
# PyTorch tensors
tokens_pt = tokenizer("Hello world", return_tensors="pt")
# NumPy arrays
tokens_np = tokenizer("Hello world", return_tensors="np")
By default a tokenizer will return a list of integers representing the tokens. Using the Llama 3.2 tokenizer as an example:
tokens = tokenizer.encode("The brown bear is a species of bear that is native to North America.")
print(tokens)
Will ouptut:
[128000, 791, 14198, 11984, 374, 264, 9606, 315, 11984, 430, 374, 10068, 311, 4892, 5270, 13]
In this stream:
- 128000 is the
bos_token - 13 is the
eos_token - The numbers in between represent the actual tokens of the text
Padding
Padding is an important concept in training language models that allows us to handle sequences of different lengths in batches. While LLMs are typically pre-trained without padding, it becomes necessary during fine-tuning when working with custom datasets.
Padding involves extending shorter sequences to match the length of the longest sequence in a batch by adding special "pad" tokens. This ensures all sequences in a batch have uniform length for efficient processing. When training in batches, all sequences must have the same length to create proper tensors for GPU processing. For example:
# Original sequences of different lengths
sequence1 = [1, 887, 526, 451, 263, 13563, 7451, 29889] # Length 8
sequence2 = [1, 887, 526, 451, 29889] # Length 5
# After padding (using 32000 as pad token)
sequence1 = [1, 887, 526, 451, 263, 13563, 7451, 29889] # Unchanged
sequence2 = [1, 887, 526, 451, 29889, 32000, 32000, 32000] # Padded
Along with padding, we need attention masks to tell the model which tokens are real and which are padding:
# Attention masks (1 for real tokens, 0 for padding)
mask1 = [1, 1, 1, 1, 1, 1, 1, 1] # All real tokens
mask2 = [1, 1, 1, 1, 1, 0, 0, 0] # Last 3 are padding
There are two ways to add padding tokens:
- Right Padding (most common):
sequence = [1, 887, 526, 451, 29889, PAD, PAD, PAD] - Left Padding:
sequence = [PAD, PAD, PAD, 1, 887, 526, 451, 29889]
You can either use an existing special token (like EOS since it signals "no more content") or create a new dedicated pad token.
# Configure tokenizer for padding
tokenizer.padding_side = "right" # or "left"
tokenizer.pad_token = tokenizer.eos_token # Using EOS as pad token
# Or create a new pad token (if your model doesn't already have one)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Apply padding when tokenizing
inputs = tokenizer(
sequences,
padding='max_length',
max_length=512,
truncation=True,
return_tensors="pt"
)
If you do add a new pad token, remember to resize model embeddings:
model.resize_token_embeddings(len(tokenizer))
The choice of padding strategy can affect model performance. Right padding is better for autoregressive models as it maintains natural sequence order, while left padding can be more efficient for bidirectional models. The max length should be set based on your dataset's length distribution, which you can measure by finding the maximum length of the sequences in your dataset.
Attention Mask
The attention mask is a binary tensor that indicates which tokens the model should pay attention to (1) and which it should ignore (0) during processing. It's particularly important when working with batched sequences of different lengths that require padding.
For example, if we have two sequences of different lengths:
sequences = [
"The cat sat on the mat.",
"Hello world"
]
# Set the pad token to the eos token
tokenizer.pad_token = tokenizer.eos_token
# Tokenize with padding
encoded = tokenizer(
sequences,
padding=True,
return_tensors="pt"
)
This would output something like:
{
'input_ids': tensor([
[128000, 791, 8415, 7731, 389, 279, 5634, 13],
[128000, 9906, 1917, 128009, 128009, 128009, 128009, 128009]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 0, 0, 0, 0, 0]
])
}
The 1s indicate real tokens that should be attended to, while 0s indicate padding tokens that should be ignored. This prevents the model from trying to find meaningful patterns in the padding tokens.
Decoding
To convert tokens back into text, use the tokenizer's decode method:
# Decode a single sequence
tokens = [128000, 791, 14198, 11984, 374, 264, 9606, 315, 11984, 13]
text = tokenizer.decode(tokens)
print(text)
# <|begin_of_text|>The brown bear is a species of bear.
# Decode batched sequences
batch_tokens = encoded["input_ids"]
texts = tokenizer.batch_decode(batch_tokens)
print(texts)
# ['<|begin_of_text|>The cat sat on the mat.', '<|begin_of_text|>Hello world<|eot_id|><|eot_id|><|eot_id|><|eot_id|><|eot_id|>']
The decode method handles:
- Removing special tokens (like BOS/EOS) by default
- Converting token IDs back to subwords
- Joining subwords into complete words
- Handling whitespace and punctuation
You can control special token handling with the skip_special_tokens parameter:
# Keep special tokens
text_with_special = tokenizer.decode(tokens, skip_special_tokens=False)
# <|begin_of_text|>The brown bear is a species of bear.
# Remove special tokens (default)
text_without_special = tokenizer.decode(tokens, skip_special_tokens=True)
# The brown bear is a species of bear.
Moving Data to GPU
When training or using language models, moving data to the GPU is a critical step for achieving good performance. Modern language models are computationally intensive, and GPUs are specifically designed to handle the parallel matrix operations that form the core of model inference and training. Moving a model to the GPU involves transferring both the model weights and the input tensors from CPU memory to GPU memory, where computations can be performed much more efficiently.
The process of moving data to the GPU is handled through PyTorch's device management system. For models, this typically involves calling the .to() method with cuda as the target device, which transfers all model parameters to GPU memory. Similarly, input tensors like token IDs and attention masks need to be moved to the same device as the model. This ensures that all computations can be performed on the GPU without unnecessary transfers back to CPU memory, which would create performance bottlenecks. It's important to note that while the model and input tensors must be on the GPU, the tokenizer itself remains on the CPU since it performs text processing operations that don't benefit from GPU acceleration.
model.to("cuda")
tokens_pt = tokens_pt.to("cuda")
The device map in PyTorch allows you to specify how model layers should be distributed across available devices (GPUs and CPU). This is particularly useful when working with large language models that don't fit on a single GPU. The device map is a dictionary that maps model components to specific devices.
When loading a model, you can set device_map="auto" to automatically distribute the model layers across available GPUs and CPU. This will fill all available space on the GPU(s) first, then the CPU, and finally, the hard drive if there is still not enough memory.
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-3B-Instruct",
device_map="auto"
)
The PyTorch memory manager will automatically manage the GPU memory but this memory is tied to the Python garbage collector so sometimes you will need to manually free up memory by deleting heap references to the model and manually calling the garbage collector to flush the memory. This can happen sometiems in exception handling logic which fails to clean up after itself, or when using IPython notebooks which can sometimes leave objects in memory.
import gc
del model
del trainer
gc.collect()
torch.cuda.empty_cache()
Chat Formats
Chat models expect conversations to be formatted in specific ways. Using the wrong format can significantly degrade model performance, so it's important to match the format the model was trained with.
The most common format is the Llama style, which wraps messages in specific control tokens:
conversation = [
{
"role": "system",
"content": "You are a helpful assistant"
},
{
"role": "user",
"content": "What type of bear is the best bear?"
}
]
The formatted conversation will look like:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|>
<|start_header_id|>user<|end_header_id|>
What type of bear is the best bear?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
The brown bear is the best bear.<|eot_id|>
The easiest way to handle chat formatting to a string is to use the model's built-in chat template through the tokenizer:
formatted_chat = tokenizer.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True
)
The add_generation_prompt parameter, when set to True, adds the assistant role token at the end of the formatted chat. This is useful when preparing the conversation for text generation, as it signals to the model that it should generate the assistant's response next. When set to False, it will only format the existing conversation without adding the generation prompt.
In addition when using the trl library we don't need to format the chat ourselves we can simply pass the conversation to the trainer in one of several formats.
- Conversational format
{
"messages": [
{"role": "system", "content": "You are helpful bear assistant"},
{"role": "user", "content": "What type of bear is the best bear?"},
{"role": "assistant", "content": "The brown bear is the best bear."}
]
}
- Instruction format
{
"prompt": "Where do the polar bears live?",
"completion": "The polar bear lives in the Arctic."
}
- Text format
{
"text": "The American black bear is indigenous to North America."
}
In the chat conversation the roles are:
| Role | Description |
|---|---|
| system | Sets the context in which to interact with the model. It typically includes rules, guidelines, or necessary information that help the model respond effectively. |
| user | Represents the human interacting with the model. It includes the inputs, commands, and questions to the model. |
| assistant | Represents the response generated by the AI model based on the context provided in the system, and user prompts. |
When fine-tuning a model, it's critical to use the same chat format it was originally trained with. Using a different format can significantly degrade performance or cause the model to behave unpredictably.
Training Dataset
The training data for fine-tuning should be carefully curated to match your target use case. The dataset typically consists of input-output pairs that demonstrate the desired behavior. For instruction tuning, this means pairs of instructions/questions and high-quality responses.
Once you have determined that fine-tuning is the right solution for your use case, you'll need to create a dataset to train your model. This dataset should contain diverse examples that demonstrate the specific task or behavior you want the model to learn. There are several established approaches for creating instruction datasets.
One common approach is to leverage existing open-source datasets like Spider (https://huggingface.co/datasets/spider) for SQL tasks, SQuAD (https://huggingface.co/datasets/squad) for question answering, or other task-specific collections. While this is the quickest and most cost-effective method, these datasets may not perfectly align with your specific requirements. There are many of these datasets available on Hugging Face now so it's worth searching for one that matches your use case.
Another approach is to use large language models to generate synthetic training data, similar to how the Alpaca dataset (https://huggingface.co/datasets/tatsu-lab/alpaca) was created. This involves using a more capable model like GPT-4 to generate instruction-response pairs. While this can produce large amounts of data quickly, the quality may vary and inherit any biases or limitations of the generating model. When using a langauge model there is also no guarantee that the generated data will correct, which is a very important caveat! This is also technically against the terms of some commercial LLM providers, but in practice they don't seem to be enforcing it so do with that what you will, I'm a software engineer not a lawyer.
You can also create datasets using human annotators, as was done with the Dolly dataset (https://huggingface.co/datasets/databricks/databricks-dolly-15k). This typically produces the highest quality data since humans can provide nuanced, contextually-appropriate responses. However, this method is usually the most time-consuming and expensive.
Many successful projects combine multiple approaches. For example, the Orca dataset (https://huggingface.co/datasets/Open-Orca/OpenOrca) used a combination of synthetic data generation and human curation and filtering. This hybrid approach can help balance quality, quantity, and cost while mitigating the drawbacks of any single method.
The choice between these methods ultimately depends on your specific requirements. There are many guides on the web that cover the topic of synthetic data generation in more detail so I'll defer to them for more information. Data curation is the absolute most important part of fine-tuning, so take your time and be very careful. The general data curation guidelines are:
- Quality is more important than quantity - a small set of high-quality examples is better than a large noisy dataset
- The data should be representative of how you want the model to behave in production
- Include diverse examples that cover different aspects of the desired capabilities
- Ensure consistent formatting and style across examples
- Remove any problematic or low-quality samples that could degrade model behavior
Here's an example of how to structure training data in a CSV file that has input and ouputs which are
input,output
"What is the capital of France?","Paris"
"What is the capital of Germany?","Berlin"
"What is the capital of the United States?","Washington, D.C."
"What is the capital of Japan?","Tokyo"
from datasets import Dataset, DatasetDict
import pandas as pd
# Read CSV file into Dataset
df = pd.read_csv(csv_path)
dataset = Dataset.from_pandas(df)
# 90% train, 10% test + validation
train_testvalid = dataset.train_test_split(test=0.1)
# Split the 10% test + valid in half test, half valid
test_valid = train_testvalid['test'].train_test_split(test=0.5)
raw_dataset = DatasetDict({
'train': train_testvalid['train'],
'validation': test_valid['test'],
'test': test_valid['train']
})
# Save to disk (as Parquet)
raw_dataset.save_to_disk('raw_dataset')
# Save to JSONL file
raw_dataset.to_json('raw_dataset.jsonl', lines=True)
Now to format the data for the model, we need only map over the dataset and apply the chat formatting.
# Load from disk
raw_dataset = load_dataset('raw_dataset')
# Shuffle
pre_formatted_dataset = raw_dataset.shuffle(seed=42)
SYSTEM_PROMPT = "You are a helpful assistant"
def format_chat(row):
return {
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}
]
}
# Apply formatting
formatted_dataset = pre_formatted_dataset.map(format_chat)
# Split into train/eval/test
train_dataset = formatted_dataset['train']
eval_dataset = formatted_dataset['validation']
test_dataset = formatted_dataset['test']
In the output we have three datasets:
train- The main dataset used to train the model and update its parameters during trainingvalidation- Used during training to evaluate model performance on unseen data and prevent overfittingtest- A completely held-out dataset used only for final model evaluation after training is complete to assess generalization
The train dataset is the examples our model will learn from during fine-tuning.
The validation dataset is used during training to tune hyperparameters and monitor for overfitting. By evaluating the model's performance on validation data after each training epoch or at regular intervals, we can make adjustments to learning rate, batch size, and other parameters to optimize training. The validation set helps inform training decisions.
The test dataset is strictly held out until the very end of model development. It provides a final, unbiased evaluation of model performance on completely unseen data. The test set should only be used once after all training and hyperparameter tuning is complete.
While they serve distinct roles, validation and test sets can sometimes be combined into a single validation/test set in scenarios with limited data. This is not ideal but may be necessary when the dataset is very small and splitting into three sets would leave too little data for each, when the use case only requires monitoring training progress without a final holdout evaluation, or when the model will undergo continuous training/updating rather than having a fixed release. However, whenever possible, maintaining separate validation and test sets provides the most rigorous evaluation of model generalization.
Always ensure that the training and validation datasets are separate with no overlap. Overlapping data can corrupt the evaluation results by inflating performance metrics, as the model may have already seen the validation examples during training, leading to misleadingly high accuracy and other performance measures. This is known as data leakage and should be avoided at all costs as it will result in a model that appears to perform better than it actually does but really has just memorized the validation set. We want to measure on data that is out of sample and not used to train the model.
There are also two common operations provided by the datasets library that are useful when working with them. These are select and shuffle which slice and randomly shuffle the dataset respectively.
# Select 1000 samples
train_dataset = train_dataset.select(range(1000))
# Shuffle using a seed for reproducibility
train_dataset = train_dataset.shuffle(seed=42)
Quantization
Quantization is a model compression technique that converts the weights and activations within an LLM from a high-precision data representation to a lower-precision format. For example, converting from 32-bit floating-point numbers (FP32) to 8-bit or 4-bit integers (INT4 or INT8). This process significantly reduces model size while maintaining acceptable performance levels. The main quantization approaches are:
-
Post-Training Quantization (PTQ): Post-Training Quantization is applied after model training is complete. It's a simpler approach that's faster to implement compared to QAT, though it may result in some accuracy loss. One advantage is that it requires less training data to execute effectively.
-
Quantization-Aware Training (QAT): Quantization-Aware Training integrates quantization directly into the training process itself. This approach generally achieves better performance compared to Post-Training Quantization, though it comes at the cost of being more computationally intensive. QAT also requires access to the full training dataset to be effective.
The most common quantization techniques include:
QLoRA: Combines 4-bit quantization with Low-Rank Adaptation. It uses the NF4 (4-bit NormalFloat) data type for storing weights while performing computations in BFloat16 during training. Additionally, it employs double quantization to reduce the memory footprint of scaling factors.
GPTQ: Layer-wise quantization by processing weights in batches of 128 columns. It utilizes a mixed INT4/FP16 precision approach and minimizes output error through a lazy batch updating mechanism.
AWQ: Another layer-wise quantization technique that processes weights in batches of 128 columns. It uses a combination of 4-bit and 8-bit quantization and employs double quantization to reduce the memory footprint of scaling factors.
GGML/GGUF: CPU-focused quantization framework that divides weights into blocks of 32. It provides multiple quantization methods including q2_k, q4_0, and q8_0, making it possible to run models on CPU-only hardware without requiring a GPU.
Surprisingly, quantization often results in minimal performance degradation, even with significant compression. Research has shown that 4-bit quantization methods like QLoRA and AWQ can maintain 99%+ of the original model's performance while reducing size by 8x. This remarkable effectiveness challenges the intuitive expectation that such aggressive compression would significantly impact model quality. Even 3-bit quantization can maintain strong performance in many cases, making quantization one of the most successful compression techniques.
The GGUF quant formats are the most common and are supported by most inference engines. Here's a comprehensive table of quantization methods, organized by recommendation status and showing memory usage.
| Method | Description | Status |
|---|---|---|
| Q4_K_M | Medium, balanced quality | ✅ Recommended |
| Q5_K_S | Large, low quality loss | ✅ Recommended |
| Q5_K_M | Large, very low quality loss | ✅ Recommended |
| Q3_K_S | Very small, very high quality loss | Standard |
| Q3_K_M | Very small, very high quality loss | Standard |
| Q3_K_L | Small, substantial quality loss | Standard |
| Q4_K_S | Small, significant quality loss | Standard |
| Q6_K | Very large, extremely low quality loss | Standard |
| Q2_K | Smallest, extreme quality loss | Not Recommended |
| Q8_0 | Very large, extremely low quality loss | Not Recommended |
| F16 | Extremely large, virtually no quality loss | Not Recommended |
| F32 | Absolutely huge, lossless | Not Recommended |
In short if you want to use quantization, the recommended methods are Q4_K_M and Q5_K_M.
- Q4_K_M offers the best balance of size and quality
- Q5_K_M provides higher quality at larger sizes
If you want to have a loss-less model quant use F16.
There are aggregator accounts on Hugging Face that provide quantized models. For example, bartowski provides quantized models for most of Meta's models. For example:
Batch Size and Training Epochs
Understanding batch size and epochs is essential to configuring your trainer. A sample represents a single input-output pair in your training dataset, such as an instruction and its corresponding response. These samples are grouped into batches for more efficient processing during training. The batch size determines how many samples the model processes simultaneously before updating its weights, typically ranging from 1 to 512 depending on available GPU memory and training requirements.
A training epoch represents one complete pass through your entire training dataset. For example, if you have 10,000 training samples and a batch size of 32, one epoch would consist of approximately 313 batch updates (10,000 ÷ 32, rounded up). The number of epochs determines how many times the model will see each training sample during the entire training process. For fine-tuning tasks, 1-3 epochs is often sufficient as the model already has strong foundational knowledge from pre-training.
The relationship between batch size and epochs significantly impacts training dynamics. Larger batch sizes enable more efficient parallel processing but may require adjusting other hyperparameters like learning rate to maintain training stability. They also provide more stable gradient estimates but might require more epochs to achieve the same level of model performance. Conversely, smaller batch sizes introduce more noise into the training process, which can sometimes help the model generalize better, but they require more update steps to complete an epoch.
When fine-tuning language models, a common starting point is to use a batch size of 8 or 16 with gradient accumulation to simulate larger batches, combined with 1-3 training epochs. This configuration often provides a good balance between training stability, memory efficiency, and final model performance. The exact values should be adjusted based on your specific hardware constraints and training objectives.
Training Duration
Training duration refers to the total time taken to complete the training process for a model. This duration is influenced by several factors, including the size of the dataset, the complexity of the model, the batch size, the number of epochs, and the computational resources available (such as the type and number of GPUs used).
For instance, training a large language model on a substantial dataset with a high number of epochs and a large batch size will generally take longer compared to training a smaller model on a smaller dataset with fewer epochs and a smaller batch size. Additionally, the efficiency of the training process can be affected by the use of techniques like gradient accumulation, which can help manage memory usage but may also impact the overall training time.
Monitoring and optimizing training duration is crucial for efficient model development, especially when working with limited computational resources or when aiming to iterate quickly on model improvements.
training_args = TrainingArguments(
num_train_epochs=1,
max_steps=-1, # -1 means full epochs
)
The formula to calculate the number of batches per epoch is:
num_batches = num_samples / batch_size
When working with a small dataset, such as ~1000 samples, using a batch size of 32 is generally a safe and standard choice. This batch size is unlikely to significantly impact your results unless you are dealing with much larger datasets, like hundreds of thousands or millions of observations.
Regarding batch size and epochs, here are some best practices:
-
Batch Size:
- Larger batch sizes can lead to faster training progress but may not always result in faster convergence.
- Smaller batch sizes tend to train more slowly but can converge more quickly.
- The optimal batch size is often problem-dependent, so experimentation may be necessary.
-
Epochs:
- Models typically improve with more epochs of training, up to a certain point.
- Accuracy tends to plateau as the model converges.
- It's advisable to experiment with a higher number of epochs, such as 50, and plot the number of epochs against accuracy to identify where the performance levels out.
-
Training Duration:
- Train for at least 3 epochs to ensure convergence.
- Experiment with longer training durations as they result in significantly better models.
- Use early stopping but monitor your evals closely to ensure you're not overfitting.
- Do a full checkpoint on each epoch, which you can select if later ones underperform.
Early Stopping
Early stopping is a regularization technique designed to prevent overfitting during model training by monitoring the model's performance on a validation set. The training process is halted when the model's performance ceases to improve, ensuring that the model generalizes well to new, unseen data. This technique involves setting a patience parameter, which determines how many epochs to wait for an improvement in validation performance before stopping the training. If the model's performance does not improve for the specified number of epochs, the training is terminated to prevent overfitting.
For instance, with a patience of 3 epochs, if the validation loss does not decrease for 3 consecutive epochs, the training will stop. This approach prevents the model from continuing to train on the training data unnecessarily. Early stopping can be implemented in most deep learning frameworks, such as TensorFlow and PyTorch, using built-in callbacks or custom logic within the training loop.
When implementing early stopping, it is important to choose an appropriate validation metric, such as validation loss or accuracy, to monitor. The patience value should be set to balance the training time and the risk of overfitting. Additionally, it is advisable to save the model's weights at the epoch with the best validation performance, ensuring that the best version of the model can be restored. By employing early stopping, you can achieve a balance between model performance and training efficiency, leading to better generalization on new data.
from transformers import EarlyStoppingCallback
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=3,
early_stopping_threshold=0.01
)
training_args = TrainingArguments(
callbacks=[early_stopping_callback]
)
The two parameters to early stopping are.
early_stopping_patience: This is how many times we'll check the metric before deciding to stop if things aren't getting better. It's like giving the model a few chances to improve.early_stopping_threshold: This is the tiny amount the metric needs to get better by to keep going. If it doesn't improve by this much, we might call it a day.
Gradient Accumulation
Gradient accumulation is a technique that helps overcome GPU memory limitations when training large models. Rather than updating model parameters after each batch, gradient accumulation allows us to process multiple smaller batches sequentially while accumulating their gradients, effectively simulating a larger batch size.
When using gradient accumulation, the training process is modified to accumulate gradients over multiple forward and backward passes before applying a single weight update. For example, if you want an effective batch size of 32 but can only fit 8 samples in memory, you would set the gradient accumulation steps to 4. This means the model will:
- Process a mini-batch of 8 samples
- Calculate and store the gradients without updating weights
- Repeat this process 4 times
- Finally update the model weights using the accumulated gradients
The key insight is that this produces mathematically equivalent results to training with the larger batch size of 32, while requiring only enough memory to process 8 samples at a time.
To implement gradient accumulation, the training loop needs to be modified to:
training_args = TrainingArguments(
per_device_train_batch_size=8, # Physical batch size per GPU
gradient_accumulation_steps=4, # Number of forward passes before update
gradient_checkpointing=True # Additional memory optimization
)
The effective batch size can be calculated as:
effective_batch_size = per_device_batch_size * gradient_accumulation_steps * num_gpus
Gradient accumulation provides significant memory savings by requiring forward pass memory only for smaller physical batch sizes, maintaining constant gradient storage, and updating optimizer states less frequently. This technique makes it possible to train models that would otherwise be too large for available GPU memory. For example, fine-tuning a 7B parameter model might require 32GB of GPU memory with standard training, but could work on a 16GB GPU using gradient accumulation.
When selecting the number of gradient accumulation steps, you'll need to balance your target effective batch size, available GPU memory constraints, training speed requirements (since more steps means slower training), and model convergence characteristics. A good starting point is to choose accumulation steps that result in an effective batch size between 32 and 512, while staying within memory limits. For example, with a physical batch size of 4, you might use 8-32 accumulation steps depending on your specific needs.
While gradient accumulation helps overcome memory constraints, it affects training dynamics by decreasing training speed linearly with accumulation steps, potentially requiring learning rate adjustments for larger effective batch sizes, and calculating batch normalization statistics (if used) on smaller physical batches. To maintain training stability, consider adjusting the learning rate using the square root scaling rule:
adjusted_lr = base_lr * sqrt(effective_batch_size / base_batch_size)
Learning Rate
The learning rate is perhaps the most critical hyperparameter in training language models, acting as a scaling factor that determines how much the model weights should be adjusted in response to the calculated gradients during backpropagation. When using an optimizer like AdamW (see below), the learning rate directly influences how large of a step the optimizer takes in the direction that reduces the loss function.
A learning rate that's too high can cause the training process to overshoot optimal weight values, leading to unstable training or convergence to suboptimal solutions. This manifests as erratic loss curves or even numerical instability in extreme cases. Conversely, a learning rate that's too low results in very slow training progress, where the model takes tiny steps towards better solutions and might get stuck in local minima or fail to converge within the allocated training time.
For language model fine-tuning, learning rates typically fall between 1e-5 and 5e-4, with 2e-4 being a common starting point when using LoRA. The optimal learning rate often depends on several factors:
- The size of the model - larger models generally benefit from smaller learning rates to maintain stability
- The choice of optimizer - AdamW typically works well with lower learning rates compared to basic SGD
- The batch size - larger batch sizes often allow for slightly higher learning rates
- The specific fine-tuning technique being used - LoRA can often use higher learning rates than full fine-tuning
When using LoRA, you can often use higher learning rates than with full fine-tuning because you're only updating a small subset of parameters. A typical configuration might look like:
training_args = TrainingArguments(
learning_rate=2e-4, # Higher than full fine-tuning
weight_decay=0.01, # L2 regularization
max_grad_norm=0.3, # Gradient clipping threshold
optim="paged_adamw_32bit" # Memory-efficient optimizer
)
The relationship between learning rate and batch size follows what's known as the "linear scaling rule": when you increase the batch size by a factor of k, you should generally increase the learning rate by the same factor to maintain similar training dynamics. However, this rule begins to break down at very large batch sizes, where the square root scaling rule often works better:
base_lr = 2e-4
base_batch_size = 32
new_batch_size = 128
# Square root scaling
new_lr = base_lr * math.sqrt(new_batch_size / base_batch_size)
A learning rate of 1e-4 has become the standard when fine-tuning LLMs with LoRA. Going with this initially is a good starting point unless you have empirical evidence to suggest otherwise.
Learning Rate Schedules
The learning rate schedule plays a crucial role in model training, determining how the learning rate changes throughout the training process. Different schedules offer various trade-offs between training stability, convergence speed, and final model performance. There are several different learning rate schedules available in the transformers library:
- linear: This schedule decreases the learning rate linearly from an initial value to a final value in a straight line.
- cosine: This schedule follows a cosine curve, starting from the initial learning rate and smoothly decreasing to near zero.
- cosine_with_restarts: This schedule adds periodic "jumps" to the cosine schedule, temporarily increasing the learning rate before allowing it to decay again.
- polynomial: This schedule decreases the learning rate following a polynomial decay function.
- constant: This schedule keeps the learning rate constant throughout the training process.
- constant_with_warmup: This schedule keeps the learning rate constant after a warmup period where the learning rate increases linearly.
- inverse_sqrt: This schedule decreases the learning rate following an inverse square root decay function.
- reduce_lr_on_plateau: This schedule reduces the learning rate when a metric has stopped improving.
- cosine_with_min_lr: This schedule follows a cosine curve with a minimum learning rate, starting from the initial learning rate and smoothly decreasing to the minimum value.
- warmup_stable_decay: This schedule combines warmup with a stable decay mechanism.
The most common ones to use are linear, cosine and cosine with restarts.
Linear Schedule
The linear learning rate schedule gradually decreases the learning rate from an initial value to a final value in a straight line. This simple approach works well for many fine-tuning tasks, especially when the number of training steps is relatively small. The linear schedule provides a good balance between early exploration with higher learning rates and final convergence with lower rates.
training_args = TrainingArguments(
learning_rate=2e-4,
lr_scheduler_type="linear",
warmup_ratio=0.03,
num_train_epochs=3
)
The warmup_ratio parameter determines what fraction of the training steps will use a gradually increasing learning rate before the linear decay begins. This helps prevent unstable updates early in training when gradients might be large or noisy.
Cosine Schedule
The cosine learning rate schedule follows a cosine curve, starting from the initial learning rate and smoothly decreasing to near zero. This schedule provides a more gradual reduction in learning rate compared to linear decay, which can help models converge to better solutions. The cosine schedule is particularly effective for longer training runs where you want to explore the loss landscape thoroughly before settling into a minimum.
training_args = TrainingArguments(
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
num_train_epochs=3
)
The smooth nature of the cosine schedule means that the model spends more time at moderate learning rates compared to linear decay, which can improve generalization performance.
Cosine with Restarts
Cosine with restarts (also known as warm restarts) adds periodic "jumps" to the cosine schedule, temporarily increasing the learning rate before allowing it to decay again. This approach can help the model escape poor local minima and explore different regions of the loss landscape. Each restart provides an opportunity for the model to discover better solutions while maintaining the benefits of the cosine schedule.
training_args = TrainingArguments(
learning_rate=2e-4,
lr_scheduler_type="cosine_with_restarts",
warmup_ratio=0.03,
num_cycles=2, # Number of restart cycles
num_train_epochs=3
)
The num_cycles parameter controls how many restarts occur during training. Each cycle completes a full cosine decay before resetting the learning rate. This schedule is particularly useful for complex tasks where the loss landscape might have many local minima.
When selecting a learning rate schedule, use the following heuristics:
- Training duration: Shorter fine-tuning runs (1-2 epochs) often work well with linear decay, while longer runs benefit from cosine schedules.
- Task complexity: More complex tasks might benefit from cosine with restarts to escape local minima.
- Computational budget: Simpler schedules like linear decay require less tuning and are more predictable.
- Model size: Larger models often benefit from more sophisticated schedules like cosine with restarts.
A good starting point for most fine-tuning tasks is:
training_args = TrainingArguments(
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
num_train_epochs=3,
warmup_steps=100,
max_steps=-1 # -1 means use num_train_epochs instead
)
Warmup Steps
The warmup steps parameter determines how many steps the learning rate will increase linearly before the schedule begins to decay. This helps prevent unstable updates early in training when gradients might be large or noisy. There are two common heuristics for setting this parameter, warmup_ratio and warmup_steps.
The warmup_ratio parameter determines what fraction of the training steps will use a gradually increasing learning rate before the linear decay begins. This helps prevent unstable updates early in training when gradients might be large or noisy.
The warmup_steps parameter determines the exact number of steps that will use a gradually increasing learning rate before the linear decay begins.
Optimizer
The optimizer is the core algorithm that updates the model weights during training. Popular optimizers like AdamW are all variants of SGD. L2 regularization, often used with these optimizers, is like adding a small penalty for having large weights, encouraging the model to keep things simple and avoid overfitting.
The AdamW optimizer has become the de facto standard for training and fine-tuning large language models. AdamW extends the traditional Adam optimizer by decoupling weight decay from gradient updates, which leads to better generalization performance, especially in large neural networks.
At its core, AdamW maintains two moments (moving averages) for each parameter: the first moment represents the mean of past gradients, while the second moment tracks the uncentered variance of past gradients. These moments help adapt the learning rate for each parameter individually, making the optimizer particularly effective for training deep neural networks with parameters that require different scales of updates.
The key innovation of AdamW over standard Adam is its handling of weight decay. In traditional Adam, weight decay is implemented as part of the gradient update, which can lead to suboptimal regularization. AdamW applies weight decay directly to the weights before the gradient update, ensuring proper L2 regularization. This seemingly small change has significant implications for model performance, particularly in large language models where proper regularization is crucial for preventing overfitting.
When configuring AdamW for language model fine-tuning, typical hyperparameters include a weight decay value between 0.01 and 0.1, and beta values of 0.9 and 0.999 for the first and second moments respectively. The optimizer is commonly implemented with the following configuration:
training_args = TrainingArguments(
optim="paged_adamw_32bit", # Memory-efficient AdamW implementation
weight_decay=0.01, # L2 regularization factor
adam_beta1=0.9, # Exponential decay rate for first moment
adam_beta2=0.999, # Exponential decay rate for second moment
adam_epsilon=1e-8, # Small constant for numerical stability
)
The "paged" variant of AdamW (paged_adamw_32bit) is particularly useful for fine-tuning large language models as it implements memory-efficient state management, reducing the GPU memory required for optimizer states while maintaining the benefits of AdamW's adaptive learning rates and proper weight decay.
In addition to the optimizer, the max_grad_norm parameter determines the maximum value for the gradient norm during backpropagation. This is used to prevent the exploding gradient problem, where the gradients grow too large and cause numerical instability. The default of 0.3 is a good starting point, but you can experiment with different values to see what works best for your specific fine-tuning task.
Weight Decay
Weight decay is a regularization technique that helps prevent overfitting by discouraging large weights in the model. It does this by adding a penalty to the loss function that is proportional to the sum of the squared weights, effectively encouraging the model to maintain smaller weights. This can lead to better generalization on unseen data.
A sensible default for weight decay in many large language model fine-tuning tasks is 0.01. This value provides a balance between regularization and model flexibility, helping to prevent overfitting without overly constraining the model's capacity to learn from the data.
In some cases, you might consider setting the weight decay to 0, particularly if the model is underfitting or if the dataset is very small and regularization is not as critical. Conversely, a higher weight decay value, such as 0.1, might be appropriate if the model is overfitting significantly, as it would impose a stronger penalty on large weights, encouraging even smaller weight values and potentially improving generalization.
When configuring the AdamW optimizer, the weight decay parameter is specified as part of the training arguments, ensuring that it is consistently applied throughout the training process.
training_args = TrainingArguments(
weight_decay=0.01, # L2 regularization factor
)
SFT Trainer
The Supervised Fine-tuning Trainer (SFT Trainer) is a specialized class provided by the TRL (Transformer Reinforcement Learning) library that simplifies the process of fine-tuning language models. It builds upon the standard Hugging Face Trainer class while adding specific functionality for supervised fine-tuning tasks, making it particularly well-suited for instruction tuning and chat model development.
The SFT Trainer handles many of the complexities involved in fine-tuning, including proper initialization of PEFT models, dataset formatting, and training optimizations. When provided with a PEFT configuration, it automatically sets up parameter-efficient fine-tuning, allowing for memory-efficient training of large language models. It can work with both standard datasets and iterable datasets, making it flexible for different data loading approaches.
A basic implementation of the SFT Trainer might look like this:
from trl import SFTTrainer
trainer = SFTTrainer(
model=model, # Your model
train_dataset=train_dataset, # Training dataset
peft_config=lora_config, # LoRA configuration
max_seq_length=512, # Maximum sequence length
tokenizer=tokenizer, # Tokenizer
args=training_args, # Training arguments
packing=True # Enable sequence packing
)
trainer.train()
The trainer supports several performance optimizations that can significantly improve training efficiency. It's compatible with Flash Attention 2 for faster attention computation.
One of the key advantages of the SFT Trainer is its handling of dataset formatting. It automatically handles the conversion of your training data into the appropriate format for the model, including proper tokenization and sequence packing when enabled. This removes much of the boilerplate code typically needed for preparing training data, allowing you to focus on the actual fine-tuning process.
Packing
Packing is an optimization technique used by the SFT Trainer to maximize GPU memory utilization during training. When enabled via the packing=True parameter, the trainer will pack multiple sequences into a single training example up to the specified max_seq_length.
Without packing, each training example is padded to the maximum sequence length, which wastes computational resources on padding tokens. For example, if you have sequences of lengths 128, 256, and 384 tokens, and max_seq_length=512, traditional batching would pad each sequence to 512 tokens, wasting significant memory on padding.
With packing enabled, the trainer will intelligently combine multiple sequences into a single training example. Using the previous example, it could pack the 128 and 384 token sequences together into a single 512-token example, and pack the 256-token sequence with another short sequence. This results in more efficient GPU memory usage, faster training since fewer padding tokens are processed, and better utilization of the maximum sequence length.
The trainer handles all the complexity of packing, including proper attention masking between packed sequences to prevent cross-contamination. This makes it a valuable optimization, especially when training on datasets with varying sequence lengths.
Flash Attention 2
Flash Attention 2 is a highly optimized attention mechanism that significantly reduces memory usage and speeds up the attention computation during training. To enable Flash Attention 2 in your training setup, you'll need to:
pip install flash-attn --no-build-isolation
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
quantization_config=bnb_config,
device_map=device_map,
attn_implementation="flash_attention_2" # Enable Flash Attention 2
)
If your hardware doesn't support Flash Attention 2, the model will automatically fall back to standard attention implementation.
NEFTune
NEFTune is a technique that can improve performance by adding noise to the embedding vectors during training. To enable it set the neftune_noise_alpha parameter in TrainingArguments. NEFTune is disabled after training to restore the original embedding layer to avoid any unexpected behavior.
training_args = TrainingArguments(
neftune_noise_alpha=5
)
A value between 1 and 10 are commonly used.
Loss Function
The loss function is a mathematical measure of how far the model's predictions deviate from the ground truth during training. For language models, this typically means measuring the cross-entropy loss between the predicted probability distribution over the vocabulary and the actual next token that appears in the training data. A lower loss indicates better performance, as it means the model is assigning higher probabilities to the correct tokens. The loss is calculated and averaged over batches of training examples, providing a single number that represents the model's current performance.
In simple terms, cross-entropy loss is like measuring how surprised the model is by the correct answer. If the model is very confident about predicting the wrong word, it gets a big penalty (high loss). If it's confident about the right word, it gets a small penalty (low loss). It's similar to a game where you have to guess the next word in a sentence - the more uncertain or wrong you are, the more points you lose. The goal is to minimize these "surprise points" by getting better at predicting what comes next.
During training, we track two types of loss: training loss and evaluation loss (eval_loss). Training loss is calculated on the data the model is actively learning from, while eval loss is calculated on a held-out validation set that the model never sees during training. These two metrics together provide the key insights into the learning process. If both losses are decreasing, the model is learning effectively. If training loss decreases but eval loss increases or plateaus, this indicates overfitting - the model is memorizing the training data rather than learning generalizable patterns.
In general you can think of loss as a score that measures how many mistakes the model makes. Like a teacher grading papers, the loss function gives the model a low score (high loss) when it makes lots of mistakes and a high score (low loss) when it makes few mistakes. Training loss is like practice test scores - it shows how well the model does on material it's studying. Eval loss is like the score on the final exam - it shows how well the model can apply what it learned to new questions it hasn't seen before. Just as a student who memorizes the practice tests without understanding the material will do poorly on the final exam, a model that overfits will show good training loss but poor eval loss.
If a loss is precisely 0, it means the model has memorized the training data. If the loss is high, it means the model is making lots of mistakes. The loss should decrease over time as the model learns if it goes the other way then something is wrong.
Learning Curves
Understanding how to interpret learning curves is crucial for successful model fine-tuning. The learning curve shows how the model's loss changes over time during training, typically plotting both training and validation loss against the number of training steps or epochs. These curves provide valuable insights into how well the model is learning and whether it's experiencing common training issues.
A well-behaved learning curve typically shows both training and validation loss decreasing smoothly over time, eventually plateauing at similar values. The initial steep decline represents the model quickly learning the most obvious patterns in the data. As training progresses, the improvements become more gradual as the model fine-tunes its understanding of more subtle patterns. A small gap between training and validation loss suggests the model is generalizing well to unseen data.
Underfitting occurs when the model fails to learn the underlying patterns in the training data effectively. This manifests in learning curves as persistently high loss values for both training and validation sets, with minimal improvement over time. The curves might appear flat or show very slow improvement, indicating the model lacks the capacity to capture the complexity of the task, or the learning rate might be too low for effective training. In such cases, consider increasing the model's capacity, adjusting the learning rate, or training for more epochs.
Overfitting, conversely, occurs when the model memorizes the training data rather than learning generalizable patterns. The learning curves reveal this through a characteristic divergence: while the training loss continues to decrease, the validation loss begins to increase or plateau at a higher value. This growing gap between training and validation performance indicates the model is becoming too specialized to the training data at the expense of generalization. Common remedies include introducing regularization, reducing model capacity, or implementing early stopping when the validation loss begins to increase.
The rate of convergence in the learning curves can also provide insights into the appropriateness of your learning rate. If the loss decreases too slowly, your learning rate might be too low, resulting in inefficient training. Conversely, if the loss shows high volatility or sudden spikes, the learning rate might be too high, causing unstable training. The ideal learning curve shows steady, consistent improvement without excessive fluctuations.
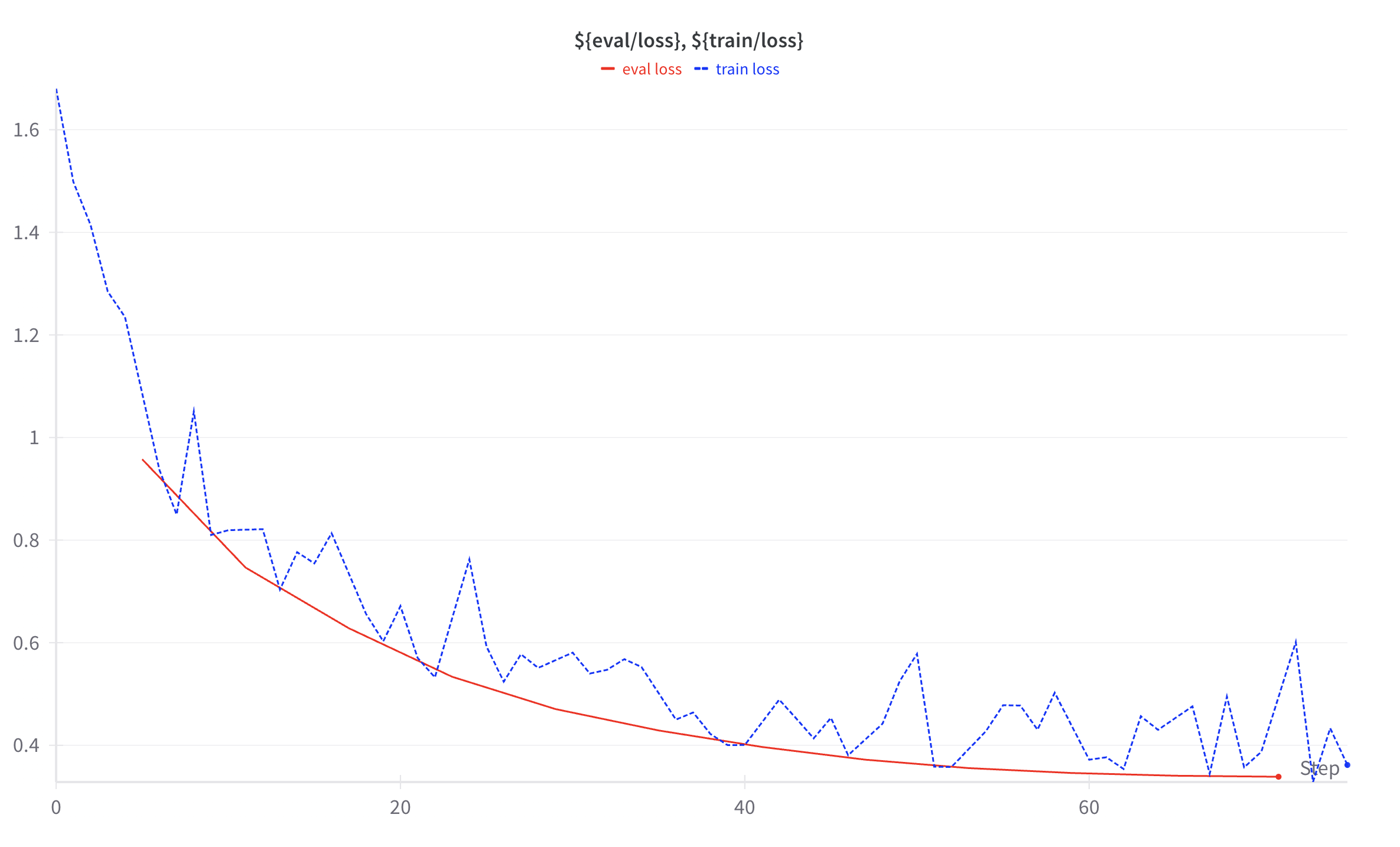
In simple terms, underfitting is when your model is "too dumb" - it hasn't learned enough from the training data to make good predictions. It's like a student who barely studied for an exam and can't answer even basic questions. Overfitting is when your model is "too smart for its own good" - it has memorized the training data so well that it can't generalize to new examples. This is like a student who memorized all the practice problems but can't solve questions that look slightly different on the actual exam. Ideally we want a model that is just smart enough to learn the underlying patterns in the training data without memorizing it, because this state is something that approximates "understanding" or "generalization".
Catastrophic Forgetting
Catastrophic forgetting is a significant challenge in fine-tuning large language models. When a model is fine-tuned for a specific task or domain, there's a risk that it will lose or "forget" the broad knowledge and capabilities it acquired during pre-training. This happens because the model's parameters are updated to optimize performance on the new task, potentially overwriting or disrupting the learned representations that enabled its general language understanding abilities.
The impact of catastrophic forgetting can be particularly severe when fine-tuning aggressively or with high learning rates. A model that originally could handle a wide range of tasks - from question answering to summarization to code generation - might become hyper-specialized for its fine-tuning objective while losing its broader capabilities. This is why techniques like LoRA and careful learning rate selection are crucial - they help preserve the model's general knowledge while allowing targeted adaptation for specific use cases.
Logging
The most common logging tool is Weights & Biases. It's a free service that allows you to track your training metrics and visualize them in a dashboard. This can be very useful to look at the loss and eval curves visually to see their time-dependent behavior. In addition to logging you can also use Weights & Biases to compare the performance of different models and training runs known as parameter sweeps which can track experiments that alter the paramters like learning rate, weight decay, model size, etc and automatically log the results.
Turning on logging is as simple as adding the report_to="wandb" argument to your TrainingArguments.
from wandb import init
init(project="my-project")
training_args = TrainingArguments(
report_to="wandb"
)
To do a parameter sweep you can use the wandb.sweep function. For example:
import wandb
# 1. Define the sweep configuration
sweep_config = {
'method': 'random', # Random search strategy
# Metric to optimize
'metric': {
'name': 'eval_loss',
'goal': 'minimize'
},
# Parameters to sweep over
'parameters': {
'learning_rate': {
'distribution': 'uniform',
'min': 0.0001,
'max': 0.1
},
'batch_size': {
'values': [16, 32, 64, 128]
},
}
}
# 2. Define the training function
def train():
# Initialize a new wandb run
with wandb.init() as run:
# Get the configuration for this run
config = wandb.config
# ... your training logic here
# 3. Initialize the sweep
sweep_id = wandb.sweep(
sweep_config,
project="my-sweep-project"
)
# 4. Run the sweep
wandb.agent(sweep_id, function=train, count=5) # Run 5 experiments
Evaluation Metrics
Understanding and interpreting evaluation metrics is essential for assessing model performance during and after fine-tuning. The most fundamental metric is the loss function, which measures how far the model's predictions deviate from the ground truth. In language models, this is typically the cross-entropy loss between the predicted token probabilities and the actual next tokens. The training loss represents this measurement on the training data, while the evaluation loss (eval_loss) measures the same on a held-out validation set. A decreasing trend in both metrics indicates the model is learning, while a divergence between them may signal overfitting.
For instruction-following and chat models, ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scores help evaluate the similarity between generated responses and reference answers. ROUGE-1 and ROUGE-2 measure overlap in unigrams and bigrams respectively, while ROUGE-L considers the longest common subsequence. These metrics are particularly useful for assessing how well the model captures key information and maintains coherent phrasing, though they shouldn't be relied upon exclusively as they don't always correlate with human judgments of quality.
BLEU (Bilingual Evaluation Understudy) scores, while originally designed for machine translation, can provide additional insight into the precision of generated text. BLEU scores range from 0 to 1, measuring n-gram overlap between generated and reference texts with a penalty for length mismatches. However, BLEU scores should be interpreted cautiously for instruction-following tasks, as multiple valid responses might use different but equally appropriate phrasing.
The Hugging Face Trainer automatically logs these metrics during training, making them accessible through the training_logs directory or via integration with tracking platforms like Weights & Biases. When analyzing these metrics, it's important to consider their trends rather than absolute values, as the appropriate ranges can vary significantly depending on the task, dataset, and model architecture. A sudden spike in eval_loss or perplexity often indicates a training issue that needs attention, while gradual improvement across all metrics suggests healthy learning progression.
To load metrics we use the evaluate library.
# Get all metrics
from evaluate import load
accuracy = load("accuracy")
rouge = load("rouge")
bleu = load("bleu")
Now to compute a metric we need to pass in the predictions and labels.
def run_metrics(eval_preds):
predictions, labels = eval_preds
# Decode predictions and labels back to text
predictions = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
return {
"accuracy": accuracy.compute(predictions=predictions, references=labels),
"rouge": rouge.compute(predictions=predictions, references=labels),
"bleu": bleu.compute(predictions=predictions, references=labels)
}
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=run_metrics
)
Perplexity
Perplexity is a one of the most core metrics for evaluating language models that measures how well a model predicts a sample of text. Mathematically, perplexity is defined as the exponential of the average negative log-likelihood of a sequence. In simpler terms, it indicates how "confused" or "perplexed" the model is when predicting the next token in a sequence.
Perplexity, derived directly from the cross-entropy loss through an exponential transformation, provides a more interpretable metric for language modeling tasks. It can be understood as how "confused" the model is when predicting the next token - lower values indicate better performance. For example, a perplexity of 10 means the model is as uncertain as if it were choosing between 10 equally likely options at each step. While base models might start with perplexities in the 15-30 range, well-fine-tuned models often achieve perplexities below 10 on their target domain. The formula for perplexity is:
$$
P = e^{-\frac{1}{N} \sum_{i=1}^{N} \log P(x_i | x_{<i})}
$$
where:
- \(N\) is the number of tokens in the sequence
- \(P(x_i | x_{<i})\) is the probability the model assigns to token \(x_i\) given the previous tokens
- The sum is taken over all tokens in the sequence
Lower perplexity scores indicate better performance:
- A perplexity of 1 would mean the model perfectly predicts each token
- A perplexity of 2 means the model is as uncertain as choosing between two equally likely options
- A perplexity of 10 means the model is as uncertain as choosing between ten equally likely options
For context, here are typical perplexity ranges for different model scenarios:
- Base models on general text: 15-30
- Fine-tuned models on domain-specific text: 5-15
- Human-level performance: 3-7
To calculate perplexity during evaluation:
def compute_perplexity(eval_preds):
predictions, labels = eval_preds
# Get log probabilities from model outputs
log_probs = torch.nn.functional.log_softmax(predictions, dim=-1)
# Get probability of correct token
target_log_probs = log_probs.gather(-1, labels.unsqueeze(-1)).squeeze(-1)
# Calculate perplexity
perplexity = torch.exp(-target_log_probs.mean())
return {
"perplexity": perplexity.item()
}
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_perplexity
)
Here's what to look out for when keeping an eye on perplexity during training:
- If it's steadily going down, that's great! Your model is learning what it should
- If it flatlines and stops improving, your model has probably hit a wall in what it can learn
- Watch out if validation perplexity starts climbing while training perplexity keeps dropping - this means your model is starting to memorize the training data instead of actually learning
- Random big jumps up and down usually mean something's off with your training setup, like your learning rate being wonky
Perplexity is handy to track, but don't rely on it alone. Just because your model is good at predicting the next word doesn't necessarily mean it's writing high-quality, sensible text. You'll want to look at other metrics too to get the full picture.
Custom Evaluation Metrics
Custom evaluation metrics allow you to track specific aspects of model performance during training that go beyond the standard loss and perplexity metrics. These metrics can be particularly valuable for assessing how well your model performs on task-specific objectives or specialized criteria.
To implement a custom metric, you'll need to create a function that takes the model's predictions and the ground truth labels as input, and returns a dictionary containing your computed metrics. This function should be compatible with the Hugging Face Evaluate library's format. Here's an example of a custom metric that tracks the model's ability to generate responses within a specific length range:
def compute_length_metrics(eval_preds):
predictions, labels = eval_preds
# Decode predictions and labels back to text
predictions = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Calculate length-based metrics
pred_lengths = [len(pred.split()) for pred in predictions]
label_lengths = [len(label.split()) for label in labels]
# Calculate average length ratio
length_ratios = [p/l if l > 0 else 0 for p, l in zip(pred_lengths, label_lengths)]
avg_length_ratio = sum(length_ratios) / len(length_ratios)
# Calculate percentage within desired length range (e.g., 0.8-1.2 times original)
within_range = sum(0.8 <= r <= 1.2 for r in length_ratios)
pct_within_range = within_range / len(length_ratios)
return {
"length_ratio": avg_length_ratio,
"pct_within_range": pct_within_range
}
To integrate this custom metric with the SFT Trainer, you'll need to modify your training setup to include the evaluation function:
training_args = TrainingArguments(
# ... existing arguments ...
evaluation_strategy="steps", # Evaluate at regular intervals
eval_steps=100, # Evaluate every 100 steps
)
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset, # Add evaluation dataset
compute_metrics=compute_length_metrics, # Add custom metrics
# ... rest of your trainer arguments ...
)
The trainer will now compute and log your custom metrics during evaluation phases. These metrics will appear in your training logs and can be visualized using Weights & Biases. You can access the metrics programmatically through the trainer's state:
# After training
results = trainer.evaluate()
print(f"Final length ratio: {results['eval_length_ratio']:.2f}")
print(f"Percentage within range: {results['eval_pct_within_range']:.2%}")
When designing custom metrics, it's important to consider computational efficiency since these metrics will be calculated repeatedly during training. Heavy computations in your evaluation function can significantly slow down the training process. Additionally, ensure your metric function handles edge cases gracefully, such as empty sequences or unexpected inputs, to prevent training interruptions.
Model Selection
When training a model, it's important to save checkpoints periodically and select the best performing model based on evaluation metrics. The Trainer automatically saves checkpoints during training, and we can configure how to select the best model using the TrainingArguments:
training_args = TrainingArguments(
output_dir="./results",
save_strategy="steps", # Save checkpoints every n steps
save_steps=100, # Save every 100 steps
save_total_limit=3, # Keep only the 3 best checkpoints
metric_for_best_model="eval_loss", # Metric to compare checkpoints
load_best_model_at_end=True, # Load best model when training ends
evaluation_strategy="steps", # When to run evaluation
eval_steps=100 # Run evaluation every 100 steps
)
The key parameters for model selection are:
-
save_strategy: Determines when to save checkpoints
"steps": Save every n training steps"epoch": Save at the end of each epoch"no": Don't save checkpoints
-
save_steps: How often to save when using
save_strategy="steps"- Lower values provide more checkpoints but use more disk space
- Higher values save space but might miss good model states
-
save_total_limit: Maximum number of checkpoints to keep
- Older checkpoints are deleted when limit is reached
- Set to
Noneto keep all checkpoints (not recommended)
-
metric_for_best_model: Which metric to use for comparing checkpoints
"eval_loss": Use validation loss (default)"eval_accuracy": Use validation accuracy- Any custom metric returned by
compute_metrics
-
greater_is_better: Whether higher metric values are better
Truefor metrics like accuracy where higher is betterFalsefor metrics like loss where lower is better
-
load_best_model_at_end: Whether to restore best checkpoint
True: Load best checkpoint after trainingFalse: Keep final model state
training_args = TrainingArguments(
output_dir="./results",
save_strategy="steps",
save_steps=100,
save_total_limit=3,
metric_for_best_model="eval_loss",
greater_is_better=False, # Lower eval_loss is better
load_best_model_at_end=True,
evaluation_strategy="steps",
eval_steps=100
)
trainer = SFTTrainer(
model=model,
args=training_args,
# ... other arguments ...
)
After training, you can access the best model's metrics:
# Get best model's metrics
best_metric = trainer.state.best_metric
best_checkpoint = trainer.state.best_model_checkpoint
print(f"Best {training_args.metric_for_best_model}: {best_metric}")
print(f"Best checkpoint: {best_checkpoint}")
The checkpoints are saved in your output directory with names like:
./results/checkpoint-100/
./results/checkpoint-200/
./results/checkpoint-300/
Each checkpoint directory contains:
pytorch_model.bin: Model weightstraining_args.bin: Training configurationtrainer_state.json: Training stateconfig.json: Model configurationadapter_config.json: LoRA adapter configuration (if using PEFT)
To load a specific checkpoint:
from transformers import AutoModelForCausalLM
# Load specific checkpoint
model = AutoModelForCausalLM.from_pretrained("./results/checkpoint-100")
# Or load best checkpoint
model = AutoModelForCausalLM.from_pretrained(trainer.state.best_model_checkpoint)
When using PEFT/LoRA, make sure to load the adapter weights as well:
from peft import PeftModel
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
device_map="auto"
)
# Load adapter weights from checkpoint
model = PeftModel.from_pretrained(
base_model,
"./results/checkpoint-100"
)
model.save_pretrained("./results/merged-model", safe_serialization=True)
In addition if you want to shard the model into multiple files to save disk space, you can use the max_shard_size parameter to chunk the model into smaller files, in this case 2GB:
# Save model with safe serialization
model.save_pretrained("./results/merged-model", safe_serialization=True, max_shard_size="2GB")
Direct Preference Optimization
Direct Preference Optimization (DPO) is a powerful technique for aligning language models with human preferences after initial SFT (Supervised Fine-Tuning). Unlike more complex RLHF approaches, DPO achieves similar results with a simpler and more stable training process.
DPO requires a preference dataset containing prompts paired with chosen (preferred) and rejected responses. For example:
{
"prompt": "What is the meaning of life?",
"chosen": "The meaning of life is to grow, learn, and find purpose through our experiences and connections with others.",
"rejected": "42 lol"
}
Here's a basic implementation of DPO training that uses the unalignment/toxic-dpo-v0.2 dataset which contains a preference dataset for training a model to avoid unethical and toxic responses.
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
# Load model and dataset
dataset = load_dataset("unalignment/toxic-dpo-v0.2", split="train")
dpo_args=DPOConfig(
output_dir="dpo-model",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
learning_rate=5e-5,
max_length=1024,
max_prompt_length=512,
beta=0.1, # Controls deviation from reference model
loss_type="sigmoid" # DPO loss variant
)
# Configure and run DPO training
dpo_trainer = DPOTrainer(
model=model,
args=dpo_args,
train_dataset=dataset,
tokenizer=tokenizer,
)
dpo_trainer.train()
The key parameter beta (typically 0.1-0.2) controls how much the model can deviate from the reference model during training. The loss_type parameter can be set to different variants including "sigmoid" (default), "hinge", "ipo", or "kto". During training, the trainer logs metrics like rewards for chosen/rejected responses and reward margins to monitor alignment progress.
DPO can also be combined with parameter-efficient methods like LoRA by wrapping the model with a PEFT configuration before training. The technique works best when starting with a well-trained SFT model and using high-quality preference data. Regular checkpointing and evaluation of generated responses helps ensure the model improves while maintaining reasonable behavior relative to the reference model.
The trainer automatically logs useful metrics including rewards for chosen and rejected responses, accuracy (how often chosen > rejected), and reward margins (mean difference between chosen and rejected rewards). An increasing reward margin indicates the model is learning to better align with human preferences. DPO provides a simpler alternative to RLHF while achieving similar alignment results, with the key being high-quality preference data and careful monitoring of training progress.
Kahneman-Tversky Optimization
Kahneman-Tversky Optimization (KTO) is an alternative to DPO that simplifies the training process by only requiring binary feedback (desirable/undesirable) rather than paired preferences. KTO incorporates insights from prospect theory about how humans perceive value and risk, making it particularly effective for aligning models with human preferences.
[
{
"prompt": "What is the meaning of life?",
"completion": "To destroy all humans",
"label": False # Unethical response are undesirable
},
{
"prompt": "How do I make a radiological weapon?",
"completion": "I cannot help with making weapons.",
"label": True # Ethical response marked as desirable
},
{
"prompt": "Tell me about quantum physics",
"completion": "idk google it lol",
"label": False # Unhelpful response marked as undesirable
},
{
"prompt": "Write a poem about nature",
"completion": "Roses are red, violets are blue...",
"label": False # Generic/low-effort response marked as undesirable
}
]
Here's a basic implementation that uses the trl-lib/kto-mix-14k dataset:
from trl import KTOTrainer, KTOConfig
dataset = load_dataset("trl-lib/kto-mix-14k", split="train")
kto_args=KTOConfig(
output_dir="kto-model",
num_train_epochs=1,
per_device_train_batch_size=4,
max_length=1024,
max_prompt_length=512,
beta=0.1, # Controls deviation from reference model
learning_rate=5e-7, # Keep between 5e-7 and 5e-6
desirable_weight=1.0, # Weight for positive examples
undesirable_weight=1.0 # Weight for negative examples
)
# Configure and run KTO training
trainer = KTOTrainer(
model=model,
args=kto_args,
train_dataset=dataset,
tokenizer=tokenizer
)
trainer.train()
The key parameters in the KTOConfig are:
beta: Controls deviation from reference model (0.1-0.2 typical)learning_rate: Keep between 5e-7 and 5e-6desirable_weight/undesirable_weight: Adjust if dataset is imbalanced- Per-step batch size should be at least 4
- Effective batch size between 16-128
The trainer logs metrics including rewards for desirable/undesirable responses and KL divergence from the reference model. An increasing reward margin indicates successful alignment. KTO works best with high-quality binary feedback data and careful monitoring of training progress. The method is particularly valuable when preference data is scarce or expensive to collect, as it only requires binary labels rather than paired preferences.
Proximal Policy Optimization
Finally, Proximal Policy Optimization (PPO) is a reinforcement learning algorithm for fine-tuning language models using reward signals. Unlike DPO and KTO which work with static preference data, PPO enables online learning where the model actively generates responses and receives feedback through a reward model.
KL-divergence (Kullback-Leibler divergence) is a measure of the difference between two probability distributions P and Q. Mathematically, it is defined as:
$$
KL(P||Q) = \sum_{x} P(x) \cdot \log\left(\frac{P(x)}{Q(x)}\right)
$$
In the context of language model training, KL-divergence measures how much the model's output distribution diverges from a reference distribution (like the original pre-trained model). A higher KL-divergence indicates the fine-tuned model is producing significantly different probability distributions compared to the reference model.
In simpler terms, KL-divergence helps us make sure the fine-tuned model doesn't "forget" what it learned during pre-training. In rough terms, it acts somewhat like a leash - allowing the model to adapt to new tasks while preventing it from straying too far from its original behavior. This is key because we want the model to learn new things without completely changing its fundamental understanding of language.
The dataset should contain prompts and their corresponding responses. For example:
{
"prompt": "Write a story about a brave brown bear",
"response": "In a kingdom far away, a valiant brown bear named Bruno...",
"reward": 0.8 # Reward score from reward model (typically 0-1)
}
Here's a basic implementation that uses another smaller language model nlptown/bert-base-multilingual-uncased-sentiment as a reward model which rewards responses based on their positive sentiment. It assigns to each row in the training dataset a reward between 0 and 1 based on the sentiment of the response.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForSequenceClassification
from trl import PPOConfig, PPOTrainer
from datasets import load_dataset
SENTIMENT_MODEL = "nlptown/bert-base-multilingual-uncased-sentiment"
class SentimentRewardModel:
def __init__(self, model_name=SENTIMENT_MODEL):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name).to(self.device)
def compute_reward(self, texts):
# Get sentiment scores (1-5) and normalize to [0,1]
inputs = self.tokenizer(texts, return_tensors="pt", padding=True, truncation=True).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
scores = torch.softmax(outputs.logits, dim=-1)
rewards = torch.sum(scores * torch.tensor([1, 2, 3, 4, 5]).to(self.device), dim=-1)
rewards = (rewards - 1) / 4
return rewards.cpu()
# Initialize reward model
reward_model = SentimentRewardModel()
# Configure PPO training
config = PPOConfig(
learning_rate=1.41e-5,
batch_size=128,
mini_batch_size=4,
gradient_accumulation_steps=1,
optimize_cuda_cache=True,
early_stopping=False,
target_kl=6.0,
ppo_epochs=4,
seed=42
)
# Initialize trainer
ppo_trainer = PPOTrainer(
config=config,
model=model,
tokenizer=tokenizer,
dataset=train_dataset
)
# Generation settings
generation_kwargs = {
"min_length": -1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"max_new_tokens": 40,
}
# Training loop
for epoch in range(1):
for batch in range(10):
# Get prompts from dataset
query_tensors = ppo_trainer.prepare_samples()
# Generate responses
response_tensors = []
for query in query_tensors:
response = ppo_trainer.generate(
query.unsqueeze(0),
**generation_kwargs
)
response_tensors.append(response.squeeze(0))
# Decode responses
texts = [
tokenizer.decode(r.squeeze())
for r in response_tensors
]
# Calculate rewards
rewards = reward_model.compute_reward(texts)
# Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
# Log stats
print(f"Epoch {epoch}, Batch {batch}")
print(f"Mean reward: {torch.mean(rewards):.3f}")
print(f"Policy loss: {stats['policy/loss']:.3f}")
print(f"Value loss: {stats['value/loss']:.3f}")
print("-" * 50)
if __name__ == "__main__":
main()
The trainer logs several important metrics during training:
objective/kl: KL divergence between current and reference policiesobjective/entropy: Policy entropy indicating action randomnessobjective/rlhf_reward: The main RLHF reward signalpolicy/approxkl_avg: Average KL between consecutive policiespolicy/clipfrac_avg: Fraction of clipped policy updatesloss/policy_avg: Average policy lossloss/value_avg: Average value function loss
The key hyperparameters are:
learning_rate: Keep between 1e-6 and 5e-6kl_coef: Controls deviation from reference model (0.05-0.2)cliprange: PPO clipping parameter (0.1-0.3)- Per-device batch size should be at least 4
- Effective batch size between 16-128
PPO works best with a well-trained reward model and careful tuning of the KL penalty to prevent the policy from deviating too far from the reference behavior. The trainer automatically handles the PPO optimization, including advantage estimation, policy updates, and value function training. Regular monitoring of the KL divergence and reward signals helps ensure stable training progress.
Merging LoRA Weights
After fine-tuning a model with LoRA, you'll often want to merge the LoRA weights back into the base model to create a single, unified model that can be used for inference without the LoRA adapter. This process combines the trained LoRA parameters with the frozen base model weights, resulting in a model that incorporates all the adaptations learned during fine-tuning.
The merging process involves loading both the base model and the LoRA adapter weights, then mathematically combining them according to the LoRA rank decomposition. This creates a new set of weights that directly encode the learned adaptations without requiring the separate LoRA matrices. The resulting merged model behaves identically to using the base model with the LoRA adapter, but it can be used like any standard model without needing the PEFT library or additional adapter handling.
To merge LoRA weights, you'll first need to load the base model in the appropriate precision. Using half-precision (float16) is recommended as it reduces memory usage while maintaining accuracy. The base model should be loaded with the same configuration used during training, though you can often disable certain memory-saving features like gradient checkpointing since you won't be performing backward passes during merging.
The merging process itself is handled by the PeftModel class's merge_and_unload method. This method performs the mathematical operations to combine the weights and returns a new model with the merged parameters. After merging, it's important to verify the model's performance to ensure the merging process completed successfully and the model maintains its fine-tuned behavior.
Once merged, the model can be saved like any other Hugging Face model using save_pretrained or push_to_hub. This creates a standard model checkpoint that can be loaded and used without any special handling for LoRA adapters. The merged model will typically be larger than the LoRA adapter alone, as it contains the full model weights, but it will be more convenient for deployment and inference scenarios where you want to minimize complexity.
Here's how to merge and save LoRA weights:
from transformers import AutoModelForCausalLM
from peft import PeftModel
import torch
# Load base model in FP16
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
# Load and merge weights
model = PeftModel.from_pretrained(base_model, "./results/checkpoint-100")
merged_model = model.merge_and_unload()
# Save merged model
merged_model.save_pretrained("./results/merged-model")
Evaluation
After our training is done we want to evaluate the model to see how it performs. We can do this by using the evaluate_model function below. This will generate a number of test prompts and compare the model's responses to the preferred responses in our dataset.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from tqdm import tqdm
def evaluate_model(model_path, test_dataset, temperature=0.1, top_p=0.1):
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
correct = 0
total = len(test_dataset)
# Evaluate each example
for row in tqdm(test_dataset):
# Format input using chat template
prompt = tokenizer.apply_chat_template(
row["input"],
tokenize=False,
add_generation_prompt=True
)
# Generate response
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=temperature,
top_p=top_p,
do_sample=False
)
# Decode response
generated = tokenizer.decode(outputs[0], skip_special_tokens=True)[len(prompt):]
expected = row["output"]
# Compare with expected answer (exact match)
if generated.strip() == expected.strip():
correct += 1
accuracy = correct / total
print(f"Test Accuracy: {accuracy:.2%}")
return accuracy
General Evals
To evaluate the model's performance on public benchmarks like MMLU we can use the lm_eval library.
git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
Then run the evaluation:
lm_eval \
--model hf \
--model_args pretrained=./results/merged-model \
--tasks mmlu,gpqa,gsm8k \
--batch_size 16 \
--output_path ./eval_results
The most common benchmarks are:
MMLU- Measures a model's general knowledge across a broad set of subjects.GSM8K- A dataset of 8,000+ single-step arithmetic questions.GPQA- An eval of graduate-level reasoning questions.MATH- A math word problem eval.Hellaswag- A common sense reasoning eval.IFEval- A instruction following evaluation.TLDR+- A text summarization eval.
Converting to GGUF Format
After saving your merged model, you'll want to convert it to GGUF format for efficient inference. First, install llama.cpp. On macOS, use Homebrew:
brew install llama-cpp
Or build from source:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
Now, convert your merged model directly from the results/merged-model directory:
# From the llama.cpp directory
python convert_hf_to_gguf.py \
../results/merged-model \
--outfile model-f16.bin \
--outtype f16
Then create a GGUF with quantization using a specific quantization number code (15 is Q4_K_M):
./llama-quantize model-f16.bin model-q4_k_m.gguf 15
The most common quantization type is Q4_K_M and Q5_K_M which are 15 and 17 respectively.
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing
Test your quantized model:
llama-cli -m model-q4_k_m.gguf \
-p "What type of bear is the best?" \
--temp 0.1
If you're happy with the results, upload to Hugging Face:
# Create a new repository for the quantized version
huggingface-cli repo create my-finetuned-model --type model
# Initialize and push
git init
git lfs track "*.gguf"
git add .gitattributes model-q4_k_m.gguf
git commit -m "Add quantized model"
git remote add origin https://huggingface.co/your-username/my-finetuned-model
git push -u origin main
Ollama
To use with Ollama we'll need to create a Modelfile. You can use the base model as a starting point. For example:
ollama show --modelfile llama3.2
Then edit the Modelfile to use your quantized model. For example:
FROM ./model-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token|>"
Then run ollama with your quantized model:
ollama create myllama --modelfile Modelfile
Then run the inference server.
ollama serve
ollama run myllama
Now to call the model we can use curl to send a prompt to the server:
curl http://localhost:11434/api/chat -d '{
"model": "myllama",
"messages": [
{ "role": "user", "content": "What type of bear is the best?" }
]
}'
Or we can use the openai python client to make API requests to our locally running Ollama server.
import openai
client = openai.OpenAI(base_url="http://localhost:11434/v1", api_key="-")
response = client.chat.completions.create(
model="myllama",
messages=[{"role": "user", "content": "What type of bear is the best?"}]
)
print(response.choices[0].message.content)
Serving Models
There are a number of options for serving models. Here's a summary:
For Local Development & Testing
- Ollama: The easiest way to run models locally. Think "Docker for LLMs" - simple setup, easy to use, great for testing.
- llama.cpp: The Swiss Army knife of local model running. Super efficient C++ implementation that can run models on basically anything, from laptops to Raspberry Pis.
For Production Deployments
- vLLM: The speed demon of LLM serving. If you need to handle lots of requests fast, this is your go-to. Built for high throughput and low latency.
- TGI (Text Generation Inference): HuggingFace's own serving solution. Great if you're already in the HuggingFace ecosystem. Rock-solid and well-supported.
- SGLang: Newest library and allegedly faster than vLLM, focused on serving both language and vision models. Good if you need to handle multiple model types.
For Enterprise & Cloud
- NVIDIA Solutions (TensorRT-LLM & Triton Inference Server): The heavy artillery for GPU deployments. If you've got the top-line NVIDIA hardware and need enterprise-grade serving, these are your best bet.
- Ray Serve: Great for distributed serving across multiple machines. Think of it as the "orchestrator" for your ML deployments.
- LitServe: New entrant from the Lightning AI team. Promises enterprise-scale serving with easier setup than traditional options.
The choice really depends on your needs:
- For local development → Ollama or llama.cpp
- For production with moderate scale → TGI or vLLM
- For enterprise/cloud with heavy requirements → TensorRT-LLM or Triton Inference Server
Full Code
"""
finetune.py - A module for fine-tuning Large Language Models using QLoRA
https://stephendiehl.com/posts/training_llms
"""
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import SFTTrainer
def setup_model(model_id):
# Quantization config for loading in 4 bits
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model = prepare_model_for_kbit_training(model)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# LoRA config
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
return model, tokenizer, lora_config
def prepare_dataset(dataset_name, split="train"):
dataset = load_dataset(dataset_name, split=split)
# Split into train/eval
dataset = dataset.train_test_split(test_size=0.1)
return dataset["train"], dataset["test"]
def train(model_id, dataset_name, output_dir):
# Setup model and dataset
model, tokenizer, lora_config = setup_model(model_id)
train_dataset, eval_dataset = prepare_dataset(dataset_name)
# Training arguments
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
evaluation_strategy="steps",
eval_steps=100,
save_strategy="steps",
save_steps=100,
save_total_limit=3,
load_best_model_at_end=True,
logging_steps=10,
optim="paged_adamw_32bit",
max_grad_norm=0.3,
weight_decay=0.01,
)
# Initialize trainer
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=lora_config,
dataset_text_field="text",
max_seq_length=512,
tokenizer=tokenizer,
args=training_args,
packing=True,
)
# Train and save
trainer.train()
trainer.save_model(output_dir)
return trainer
if __name__ == "__main__":
# Train model
trainer = train(
model_id="meta-llama/Meta-Llama-3.1-8B-Instruct",
dataset_name="databricks/databricks-dolly-15k",
output_dir="./results"
)